2025-05-09
23~ minutes
Esto es un intento de “apuntes”. Es un frankestein de fragmentos sacados del libro Tanenbaum - Organización del Computador, un enfoque estructurado y Linda Null - Essentials of Computer Organization and Architecture, siguiendo como guía los PDF de las clases.
Es una máquina electrónica digital programable para el tratamiento automático de la información, capaz de recibirla, almacenarla, operar sobre ella mediante procesos determinados y suministrar los resultados de dichas operaciones.
Se refiere a los atributos de un sistema visibles al programador, que tienen un impacto directo en la ejecución lógica de los programas: Tipos de datos, instrucciones disponibles, modos de direccionamiento de memoria, mecanismos de E/S.
Se refiere a los componentes y las interconexiones que implementan la arquitectura especificada. Incluye todos los detalles de hardware invisibles al programador; por ejemplo la tecnología de memorias usada, si una instrucción es microprogramada o no, las señales de control entre los componentes de hardware, si el procesador ejecuta instrucciones en paralelo o no.
Podemos ver a la computadora como una jerarquía de niveles, o una jerarquía de máquinas (virtuales) montadas una sobre la otra, cada una definiendo un lenguaje con el que opera el nivel superior.
| Nivel | Nombre |
|---|---|
| Nivel 6 | Usuario - Aplicaciones |
| Nivel 5 | Lenguajes de alto nivel |
| Nivel 4 | Lenguaje ensamblador |
| Nivel 3 | Sistema operativo |
| Nivel 2 | ISA (Instruction set architecture) |
| Nivel 1 | Microarquitectura |
| Nivel 0 | Lógica digital |
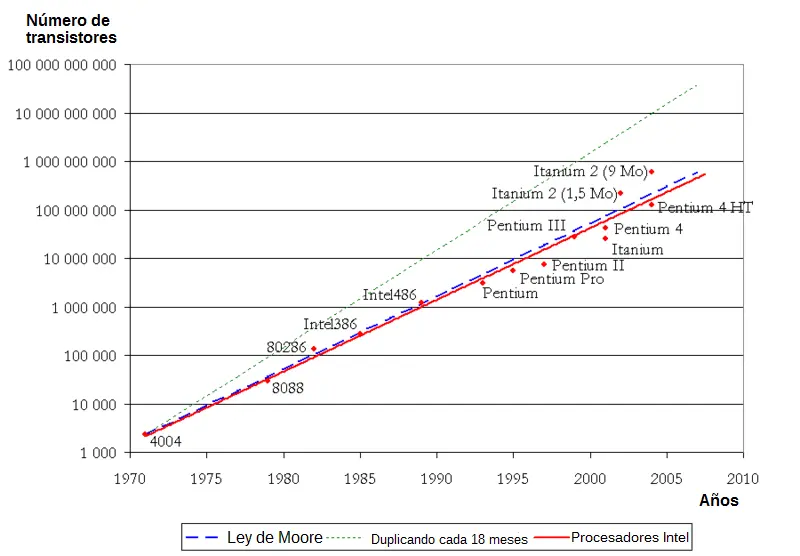
La ley de Moore expresa que aproximadamente cada dos años se duplica el número de transistores en un circuito integrado.
En los días tempranos de las computadoras, programar era sinónimo de conectar cables. No existían una arquitectura en capas, por lo que programar una computadora era más una hazaña de ingeniería eléctrica.
Antes de completar su trabajo en el ENIAC, John W. Mauchly y J. Presper Eckert concibieron una manera más fácil de cambiar el comportamiento de su máquina calculadora. Consideraron que los dispositivos de memoria podrían proporcionar una manera de almacenar las instrucciones del programa. Esto eliminaría el trabajo de reconectar los cables cada vez que se realice un nuevo problema, o uno viejo para corregir. Ellos documentaron su idea y la propusieron para su próxima computadora, la EDVAC. Desafortunadamente, Mauchly y Eckert al estar envueltos en el proyecto secreto del ENIAC, no pudieron publicar inmediatamente su visión.
Sin embargo, esta restricción no se aplicaba para otros trabajando en en el proyecto. Una de esas personas era el profesor y matemático húngaro del Institute for Advanced Study (IAS), John Von Neumann. Después de leer la propuesta de Machley y Eckert, Von Neumann presentó la idea, y construyó la computadora IAS. Fue tan efectivo que los sistemas que usan este concepto pasaron a llamarse con su nombre.
La versión actual de la arquitectura de máquina de programas almacenados satisface al menos las siguientes características:
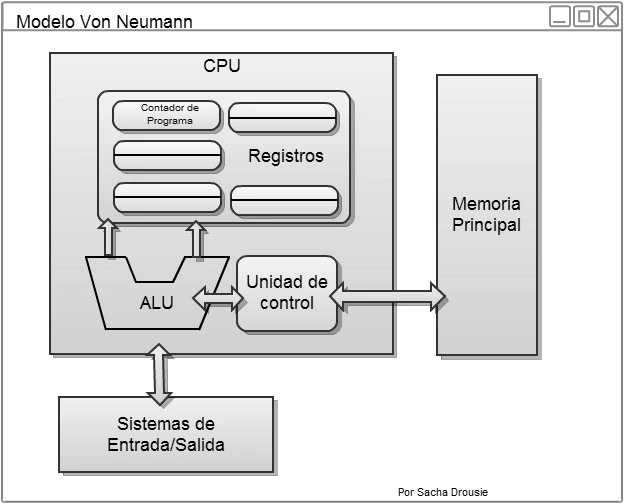
Consiste en los registros, la ALU y varios buses que conectan los componentes. La ALU suma, resta y realiza otras operaciones simples con sus entradas, y produce un resultado en el registro de salida. El contenido de ese registro de salida se envía a un registro, que posteriormente se escribe en la memoria si se desea. El proceso de de hacer pasar dos operandos por la ALU y almacenar el resultado se llama ciclo de caminos de datos y es el corazón de casi todas las CPU. Este ciclo define lo que la máquina puede hacer. Cuánto más rápido es el ciclo, más rápidamente opera la máquina.
+---------------+
,----> | A + B | <-.
| +---------------+ |
| +---------------+ |
| | | <-|
| +---------------+ |
| +---------------+ |-- Registros
| | A | <-|
| +---------------+ |
| +---------------+ |
| | B | <-´
| +---------------+
| | |
| v v
| +---+ +---+
| | A | | B |
| +---+ +---+
| | |
| v v
| +------+ +------+
| \ \ / /
| \ \__/ /
| \ ALU /
| \____________/
| |
| v
| +---------------+
`------| A + B |
+---------------+Esta arquitectura ejecuta programas en lo que se conoce como el ciclo de instrucción de Von Neumann, también llamado fetch-decode-execute (obtener-decodificar-ejecutar).
Una iteración de este ciclo funciona así:
Casi todas las instrucciones pueden dividirse en dos categorías: registro-memoria o registro-registro.
Las instrucciones registro-memoria permiten buscar palabras de la memoria a los registros, donde pueden utilizarse como entradas de la ALU en instrucciones subsecuentes. (Las palabras son las unidades de datos que se transfieren entre la memoria y los registros. Una palabra podría ser un entero) Otras instrucciones registro-memoria permiten almacenar el contenido de un registro en la memoria.
Las instrucciones registro-registro busca dos operandos de los registros, los coloca en los registros de entrada de la ALU, realiza alguna operación entre ellos (por ejemplo suma o AND) y coloca el resultado en uno de los registros.
Ejemplos de instrucciones:
La arquitectura de Von Neumann ha sido extendida para que programas y datos almacenados en medios de almacenamiento lentos, como los discos duros, pasen a memorias de accesso rápido y volátiles como la RAM antes de ejecutarse. Esta arquitectura también se ha simplificado en lo que se llama modelo de sistema de bus. Un bus es una colección de alambres paralelos para transmitir direcciones, datos y señales de control.
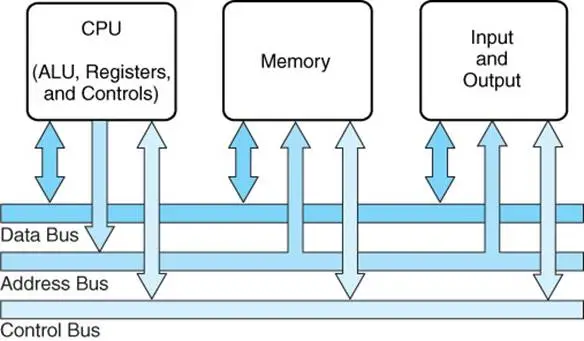
Este modelo está compuesto de los siguientes buses:
Debido a que la búsqueda de instrucciones y datos en la memoria principal es mucho más lento que la velocidad de ejecución del CPU, se produce un cuello de botella: el tiempo en el que la CPU espera la siguiente instrucción a ejecutar es tiempo desperdiciado.
Se han diseñado diferentes maneras de resolver este problema:
En el prefetch se buscan instrucciones de la memoria por adelantado. En vez de solo buscar la instrucción actual a ejecutar, se buscan las siguientes instrucciones y se guardan en unos registros llamados buffers de prebúsqueda. De esta manera, la instrucción se obtiene del buffer y no espera a que se termine la lectura de la memoria.
La memoria caché es una memoria de mayor velocidad que la memoria principal. La idea de la caché es que las palabras de uso frecuente se mantienen en esta memoria. De esta manera, cuando la CPU necesita una instrucción o dato, primero la busca en la caché. Solo recurre a la memoria principal al no encontrarlo en la caché.
Amplía la idea del prefetch. En vez de dividir en solo búsqueda y ejecución, el pipeline divide el ciclo de instrucción en etapas y las ejecuta en paralelo.
Ejemplo:
| Etapa / Tiempo | T1 | T2 | T3 | T4 | T5 | T6 |
|---|---|---|---|---|---|---|
| S1 | 1 | 2 | 3 | 4 | 5 | 6 |
| S2 | 1 | 2 | 3 | 4 | 5 | |
| S3 | 1 | 2 | 3 | 4 | ||
| S4 | 1 | 2 | 3 | |||
| S5 | 1 | 2 |
Hasta reciente, la mayoría de computadoras siguieron el modelo de Von Neumann. El problema del cuello de botella ha hecho que ingenieros busquen maneras de construir computadoras más rápidas y baratas, y compatibles con el software comercial actual. Esto ha hecho que se crearan modelos no-Von Neumann.
El modelo de Harvard es un modelo similar al modelo de Von Neumann, con la diferencia de tener 2 memorias principales: una para almacenar los programas y otro para almacenar los datos. Para esto el modelo contiene 2 buses separados, que traen las instrucciones y datos de cada memoria en paralelo. Muchas computadoras de uso general utilizan una versión modificada del modelo Harvard, dónde se utilizan los 2 buses, pero con una sola memoria principal. Arquitecturas Harvard puras son usadas para microcontroladores (System on a Chip), encontradas en sistemas embebidos como juguetes, autos, etc.
Si una pipeline es bueno, entonces 2 serán mejores. Un posible diseño consiste en traer pares de instrucciones y colocar cada una en su propio pipeline, que cuenta con su propia ALU para poder operar en paralelo. Esto requiere que las dos instrucciones no compitan por el uso de recursos, y que una no dependa del resultado de la otra.
Utilizando las mismas etapas que en el ejemplo anterior de pipeline:
+----+ +----+ +----+ +----+ +----+
| | -> | S2 | -> | S3 | -> | S4 | -> | S5 |
| | +----+ +----+ +----+ +----+
| S1 |
| | +----+ +----+ +----+ +----+
| | -> | S2 | -> | S3 | -> | S4 | -> | S5 |
+----+ +----+ +----+ +----+ +----+Es concebible usar cuatros pipelines, pero consistiría en duplicar mucho hardware. En vez de ello, se emplea otra estrategia: tener un solo pipeline pero proporcionarle varias unidades funcionales. Se le acuñó el término arquitectura superescalar a este enfoque.
S4
+-----+
,-----> | ALU | --------.
| +-----+ |
| +-----+ |
| ,--> | ALU | -----. |
| | +-----+ | |
| | v v
+----+ +----+ +----+ +------+ +----+
| S1 | -> | S2 | -> | S3 | -> | LOAD | -> | S5 |
+----+ +----+ +----+ +------+ +----+
| | ^ ^
| | +-------+ | |
| `--> | STORE | ---´ |
| +-------+ |
| +-------+ |
`-----> | float | -----´
+-------+Es un tipo especial de procesador paralelo. Un multiprocesador (parallel processor) puede ser clasificado como procesador de “memoria compartida” (cada procesador comparte la memoria global) o computadoras de “memoria distribuida” (en donde cada procesador tiene su propia memoria privada). Puesto que cada CPU puede leer o escribir en la memoria, deben coordinarse mediante software para no estorbarse entre sí.
memoria
compartida
+-----+ +-----+ +-----+ +-----+
| CPU | | CPU | | CPU | | |
+-----+ +-----+ +-----+ +-----+
| | | |
`-------+-------+------------´ Memoria privada
+-----+ +-----+ +-----+
| | | | | |
+-----+ +-----+ +-----+ memoria
| | | compartida
+-----+ +-----+ +-----+ +-----+
| CPU | | CPU | | CPU | | |
+-----+ +-----+ +-----+ +-----+
| | | |
`-------+-------+------------´Si nuestra computadora no es lo suficiente rápida o potente, en vez de crear una computadora más rápida y potente, ¿Por qué no simplemente usar múltiples computadoras? Esto es lo que la multicomputadora (parallel computing) hace. Las CPU de una multicomputadora se comunican enviándose mensajes entre sí. En sistemas grandes, tener cada computadora conectada a todas las demás no resulta práctico, por lo que se utilizan topologías para la conección. Esto resulta en que la comunicación entre 2 computadoras tiene que pasar por computadoras intermedias.
Arquitecturas de múltiples núcleos son máquinas de procesamiento paralelo que permite múltiples unidades de procesamiento (cores) en un solo chip. Dual-core tiene 2 núcleos, Quad-core 4 núcleos, y así. ¿Y qué es un core? En vez de una sola unidad de procesamiento en un chip, múltiples núcleos son colocados y ejecutados en paralelo. Cada unidad posee su propio ALU y registros, pero todos comparten memoria y recursos.
Hay que diferenciar entre multinúcleo y multiprocesador. Un multiprocesador contiene múltiple CPU conectadas a la placa madre separadamente. En un CPU con multinúcleos, cada unidad está integrada en el mismo chip, por lo que es posible reemplazar un CPU de un solo núcleo por otro con más núcleos.
Cómo se mencionó anteriormente, la memoria es la parte de la computadora en la que se almacenan programas y datos. La memoria también se la conoce como almacén (store) o almacenamiento (storage), aunque se usa comúnmente el término almacenamiento para referirse a la memoria en disco.
La organización de una computadora depende considerablemente en como representa números, letras e información de control.
La unidad de información más básica de una computadora digital se llama bit, que es la contracción de binary digit. En el sentido concreto, un bit no es más que el estado de “apagado” o “encendido” en el circuito de una computadora.
Una computadora que utiliza aritmética binaria es “eficiente”. Cuánto más valores sea necesario distinguir, y menor separación haya entre valores adyacentes, menos confiable será la memoria. El sistema de numeración binario sólo requiere distinguir entre dos valores; por tanto, es el método más confiable para codificar información digital.
En 1964, los diseñadores del mainframe IBM System/360 establecieron una convención de usar grupos de 8 bits como la unidad básica de almacenamiento de computadora direccionable. Llamaron a esta colección de 8 bits un byte.
Las palabras de una computadora consisten de 2 o más bytes adyacentes direccionables y que casi siempre se se manipulan colectivamente.
El tamaño de una palabra representa el tamaño de los datos más eficiente para una arquitectura en particular. Las palabras pueden ser de 16 bits, 32 bits, 64 bits o cualquier otro valor que tenga sentido para una arquitectura.
Un byte de 8 bits puede ser dividido en 2 partes de 4 bits llamadas nibbles. Cómo cada bit de un byte tiene un valor dentro de un sistema de numeración posicional, el nibble conteniendo el valor menos significativo es llamado nibble de orden bajo (low-order nibble), y la otra mitad nibble de orden alto (high-order nibble).
Las memorias consisten en varias celdas, cada una de las cuales puede almacenar un elemento de información. Cada celda tiene un número, su dirección, con el cual los programas pueden referirse a ella. Si una memoria tiene n celdas, tendrán las direcciones del 0 a n - 1. Todas las celdas de una memoria contienen el mismo número de bits. Si una celda consta de k bits, podrá contener 2^k combinaciones de bits distintas.
Las computadoras que emplean números binarios expresan las direcciones como binarios. Si una dirección tiene m bits, el número máximo de celdas direccionables es 2^m. El número de bits de la dirección determina el número máximo de celdas direccionables directamente en la memoria y es independiente del número de bits por celda.
Los bytes de una palabra pueden enumerarse de izquierda a derecha o de derecha a izquierda. Un sistema donde la numeración empieza por el extremo “grande” se llama big endian. En contraste, si empieza por el extremo “chico” hablamos de un sistema little endian.
Big Endian Little Endian
+-------------------+ +-------------------+
0 | 00 | 01 | 02 | 03 | | 03 | 02 | 01 | 00 | 0
+----+----+----+----+ +----+----+----+----+
4 | 04 | 05 | 06 | 07 | | 07 | 06 | 05 | 06 | 4
+----+----+----+----+ +----+----+----+----+
8 | 08 | 09 | 10 | 11 | | 11 | 10 | 09 | 08 | 8
+----+----+----+----+ +----+----+----+----+
12 | 12 | 13 | 14 | 15 | | 15 | 14 | 13 | 12 | 12
+----+----+----+----+ +----+----+----+----+
<----> <---->
Byte Byte
<-------------------> <------------------->
Palabra de 32 bits Palabra de 32 bitsEs importante entender que en ambos sistemas un entero de 32 bits con el valor 6 se representa con los bits 110 en el extremo derecho, y con 0 en los bits restantes en el lado izquierdo. En el esquema big endian, los bits 110 están en el byte 3 (o 7, u 11, etc.) mientras que en little endian los bits están en el byte 0 (o 4, u 8, etc.). En ambos casos, la palabra que contiene el entero tiene dirección 0.
Históricamente, las CPU siempre han sido más rápidas que las memorias. Al mejorar las memorias, también han mejorado las CPU, y la diferencia ha persistido. Lo que esta diferencia implica en la práctica es que, después de que la CPU emite una solicitud a la memoria, pasan muchos ciclos antes de que reciba la palabra que necesita. Cuanto más lenta es la memoria, más ciclos tiene que esperar la CPU.
El problema no es la tecnología, sino la economía. Los ingenieros saben como construir memorias tan rápidas como la CPU, pero para operar a la máxima velocidad tienen que estar dentro del chip del CPU (ir por el bus hasta la memoria es lento). Colocar una memoria más grande en el CPU lo hace más grande y costoso, e incluso si no fuera costoso, existen límites para el tamaño de un CPU. La decisión se reduce en tener poca memoria rápida o mucha memoria lenta.
La estrategia es combinar la memoria pequeña rápida con la memoria grande y lenta. Esta memoria rápida se llama caché.
La idea fundamental de la caché es que las palabras de uso frecuente se mantienen en el caché. Cuando la CPU necesita una palabra, la busca en el caché. Sino no la encuentra, recién ahí busca en la memoria principal.
Así que el éxito depende de qué fracción de las palabras están en el caché. Como los programas no acceden de manera aleatoria a la memoria, si una referencia a la memoria es la dirección A, entonces es probable que la siguiente referencia esté cera de A.
El hecho de que las referencias a memoria en un periodo corto de tiempo usa una fracción de la memoria total se llama principio de localidad. La idea general es que cuando se hace referencia a una palabra, ella y vecinos son traídos desde la memoria a la caché, para que el siguiente uso sea rápido.
+-----+ +-----+
| CPU | | | <-- Memoria principal
+-----+ +-----+
| |
| |
+-----+ |
| |<-- Caché |
+-----+ |
| |
`------------------+------- <--- BusSi una palabra se utiliza k veces en un tiempo corto, la computadora necesitará una referencia a la memoria lenta y k - 1 veces a la rápida. Cuando mayor sea k, mejor el desempeño.
Formalizando este cálculo podemos definir c como el tiempo de acceso al caché, m como el tiempo de acceso a la memoria principal, y h como la tasa de acierto, que es la fracción de todas las referencias que pueden satisfacerse con el caché, por ejemplo h = (k - 1) / k. La tasa de fallos se define como 1 - h, entonces el tiempo de acceso medio se calcula como c + (1 - h)m
A medida que h -> 1 todas las referencias puedes satisfacerse con el caché. Si h -> 0 se requerirá una referencia a memoria en cada ocasión, y un tiempo de acceso de c + m: tiempo c en la caché y tiempo m en memoria.
Con el principio de localidad, las memorias se dividen en en bloques de tamaños fijo. Al hablar de bloques en el caché, hablamos de líneas de caché. Cuando hay un fallo en el caché, toda la línea de caché se carga con la línea de memoria. Operar así es más eficiente, ya que es más rápido traer k palabras a la vez que traer una palabra k veces.
Un aspecto de diseño es si las instrucciones y los datos se guardan en una misma caché o en diferentes cachés. La arquitectura Harvard es la que guarda los datos e instrucciones en cachés divididos, debido al uso de 2 memorias principales en esa arquitectura. La unidad de búsqueda de instrucciones accede a instrucciones al mismo tiempo que la unidad de datos accede a datos. El caché dividido permite accesos en paralelo. Además, ya que las instrucciones rara vez se modifican durante la ejecución, el contenido del caché de instrucciones no tiene que volverse a escribirse en memoria.
El caché es obvio que incrementa el rendimiento, si la tasa de acierto es satisfactoria. Pero incrementar el tamaño solo la hace más lenta. Para obtener más caché, se utiliza jerarquía de caché multinivel: caché que utiliza caché para aumentar su rendimiento.
L1 (Level caché) es el término usado para la caché que está en el chip, la más rápida y pequeña. L1 caché también conocido como internal caché generalmente ronda un tamaño de 8KB y 64KB.
Cuando un acceso de memoria es requerido, L1 es chequeado primero. Si no se encuentra el dato, se procede al Level 2 (L2) caché. Este caché se encuentra externo al procesador, generalmente en la placa madre o en un chip separado. L2 es más grande, pero más lenta que L1. El tamaño de L2 ronda desde 64KB hasta 2MB. Si el dato no se encontró en L1 pero sí en L2, el dato es cargado en L1.
Actualmente L2 es posible encontrarlo en en el mismo chip que el CPU, por lo que la velocidad de L2 es casi la misma que L1. Ahora L3 (Level 3) es la caché que se encuentra entre el procesador y la memoria. L3 tiene puede tener hasta 32MB en tamaño.
Consideradar que el tamaño de la caché dependerá del avance tecnológico, es decir, los tamaños dados pueden ser más grandes o variar, pero en general da una idea de como varía el tamaño entre cachés.