Introducción
Esto es un intento de "apuntes". Es un frankestein de fragmentos sacados del libro Tanenbaum - Computer Networks siguiendo como guía los PDF de las clases.
|
Important
|
estos apuntes no han sido terminados aún. |
Introducción redes
Definición de red
Una red de computadoras es un conjunto de computadoras autónomas (posiblemente cada una con un SO diferente) interconectadas para intercambiar información.
Se dice que dos computadoras están interconectadas si pueden transmitir información.
La conexión puede ser alámbrica, como cables de cobre o fibra óptica, o mediante ondas de radio, como puede ser las microondas, infrarrojo, o comunicaciones satelitales.
Ejemplos de red
Red cliente-servidor
+---------+
| Cliente | -----------.
+---------+ |
+-----+ +----------+
| Red | ----------- | Servidor |
+-----+ +----------+
+---------+ |
| Cliente | -----------'
+---------+
El modelo cliente-servidor es ampliamente usado y es la base de muchas redes. En este modelo un cliente explícitamente solicita información a un servidor que contiene la información.
La realización más popular es la de las aplicaciones Web, dónde un servidor genera páginas Web basado en su base de datos en respuesta a las peticiones de los clientes que quizás actualicen dicha base de datos.
El modelo cliente-servidor es aplicable no solo cuando el cliente y servidor están en el mismo edificio, sino también cuando están alejados uno del otro.
Si miramos el modelo, la primera aproximación que vemos es que dos procesos están envueltos, uno en la máquina cliente y otro en el servidor. La comunicación toma la forma del proceso cliente enviando mensajes sobre la red al proceso servidor. El cliente espera por una respuesta. Cuando el servidor obtiene la petición, realiza el trabajo solicitado o consulta el dato solicitado y la envía de vuelta.
Máquina cliente Máquina servidor +-------------+ Petición +-------------+ | +---------+ | ----> +-----+ ----> | +---------+ | | | Proceso | | | Red | | | Proceso | | | +---------+ | <---- +-----+ <---- | +---------+ | +-------------+ Respuesta +-------------+
Red peer-to-peer
En conexiones peer-to-peer, los individuos que forman un grupo suelto se pueden comunicar con otros miembros del grupo. Cada persona puede comunicarse con una o más personas; no hay una división fija entre cliente y servidor.
Muchos sistemas peer-to-peer no tienen una base central de datos. En cambio, cada usuario mantiene una base de datos local de contenido, así como una lista de los otros miembros del grupo. Un nuevo usuario puede ir hacia otro usuario para ver su contenido y lista de miembros. Esto puede repetirse indefinidamente para formar una base de datos local amplia sobre qué hay en la red.
+------+ +------+ | PC 1 | ---------> | PC 2 | +------+ +------+ | ^ v | +------+ +------+ | PC 3 | <--------- | PC 4 | +------+ +------+
Tecnologías de redes
Personal Area Network
PANs (Personal Area Network) permite comunicar dispositivos dentro del área de una persona. Un ejemplo común es red inalámbrica que conecta una computadora con sus periféricos. Otro ejemplo sería la red que permite conectar auriculares y reloj inteligente a los smartphones.
Casi toda computadora tiene conectada un monitor, teclado, mouse e impresora. Sin conexión inalámbrica, se debe realizar mediantes cables. Para solucionar el problema de encontrar el cable adecuado, se diseñó una red inalámbrica de corto alcance llamada Bluetooth para conectar estos dispositivos sin usar cables.
En su forma simple, Bluetooth utiliza un paradigma maestro-esclavo donde la PC actúa como maestro hablando con sus dispositivos esclavos, como el mouse o el teclado. El maestro dice qué direcciones usar, qué pueden transmitir y por cuánto tiempo, qué frecuencias usar, etc.
PAN puede construirse con otras tecnologías de corto alcance.
+--------------+ +-------+
| PC (Maestro) | ---------- | Mouse |
+--------------+ +-------+
| +---------+
+------------------ | Teclado |
| +---------+
| +-----------+
`------------------ | Impresora |
+-----------+
Local Area Network
Una LAN (Local Area Network) es una red privada que opera dentro y cerca de edificios simples como una casa, oficina o fábrica. LANs son usadas generalmente para conectar computadoras personales y dispositivos eléctronicos para que puedan compartir recursos e intercambiar información.
LANs inalámbricas son omnipresentes. Ganaron popularidad en sitios donde colocar cables es costoso y tedioso, como hogares, restaurantes, oficinas, etc. En estos sistemas, cada computadora tiene un modem de radio y una antena que se usa para comunicarse con otras computadoras. En la mayoría de casos, cada computadora habla a un dispositivo llamado AP (Access Point) o router inalámbrico. Este dispositivo distribuye paquetes entre las computadoras y también entre ellas e Internet.
El estándar popular para conexiones LAN inalámbricas es la IEEE 802.11 comúnmente llamado WiFi. Funciona a una velocidad desde los 11 Mbps (802.11b) hasta 7 Gbps (802.11ad).
+--------------+ conexión cableada
| Access Point | -----------------
+--------------+
^
| inalámbrico
.-----------+-----------.
| | |
+------+ +------+ +------+
| PC 1 | | PC 2 | | PC 3 |
+------+ +------+ +------+
Las LAN cableadas usan diferentes tecnologías; las más comunes son cables de cobre, cables coaxiales y fibra óptica. Las LAN tienen un tamaño limitado, por lo que el peor caso de transmisión es conocida en adelanto. Conocer esas limitaciones ayudan a diseñar protocolos de red. Generalmente, las redes LAN corren a una velocidad de 100 Mbps hasta 40 Gbps. Tienen baja latencia y los errores de transmisión no son frecuentes.
La mayoría de redes LAN cableadas comprenden de enlaces cableados de punto-a-punto. IEEE 802.3, conocido como Ethernet, es por lejos la conexión cableada más popular. Cada computadora habla el protocolo Ethernet y se conecta a un dispositivo llamado switch. El trabajo del switch es retransmitir los paquetes entre computadoras que están conectadas a ella, usando la dirección MAC del paquete para determinar donde enviarlo.
Un switch contiene muchos puertos, el cual puede puede conectar una computadora u otro switch.
También es posible dividir una LAN física grande en dos LAN lógicas más chicas. Esta división lógica se conoce como VLAN (Virtual LAN). En este diseño separa los puertos en "colores", y permite retransmitir paquetes de tal manera que los paquetes de la computadoras "verdes" no se puedan propagar en las computadoras "rojas".
+-----------------+
| Ethernet switch |
+-----------------+ Al resto de la red
Puertos -> + + + + ------------------------
| | |
,_____/ | \______,
+------+ +------+ +------+
| PC 1 | | PC 2 | | PC 3 |
+------+ +------+ +------+
Metropolitan Area Network
Una MAN (Metropolitan Area Network) cubre una ciudad. Un ejemplo de dichas redes son las redes de televisión.
Al principio, estas redes fueron diseñadas localmente. Luego, compañías entraron al negocio obteniendo contratos con gobiernos para cablear ciudades. El siguiente paso fue programas de televisión y canales dedicados a televisión.
Cuando el Internet empezó a obtener audiencia, los operadores de TV se dieron cuenta que con algunos cambios el sistema podría proveer servicio de Internet en algunas partes sin utilizar del espectro. Desde ese punto, el sistema de Televisión por cable pasó de distribuir televisión a una red metropolitana.
Televisión por cable no es el único MAN. Desarrollo en conexiones inalámbricas de alta velocidad permitieron otro tipo de MAN, que fue estandarizada como IEEE 802.16 llamado WiMAX. Lamentablemente perdió contra tecnologías como LTE (Long Term Evolution) y 5G.
\ / / +--------+ +--------+
`/ / <-- Antena Caja de | Casa 1 | | Casa 2 |
/ /|| conexiones +--------+ +--------+
/ / || +----------+ +--+ | |
|| ---- | Cabecera | --+--- | | ------------+-----------+----
|| +----------+ | +--+ +--------+ +--------+
| | | Casa 3 | | Casa 4 |
| | +--------+ +--------+
| | +--+ | |
+----------+ `--- | | ------------+-----------+----
| Internet | +--+
+----------+
Wide Area Network
Una WAN (Wide Area Network) se extiende una área geográfica extensa, generalmente un país, continente o incluso múltiples continentes. Una WAN puede servir a una organización privada, como una red empresarial, o puede ser un servicio comercial, como una red de tránsito. Usaremos de ejemplo una compañía con diferentes oficinas en diferentes ciudades. Una WAN conectaría, por ejemplo, las oficinas en Perth, Melbourne y Brisbane. Cada una de esas oficinas contiene computadoras (hosts) que ejecutan programas de usuario. El resto de la red que conecta estos hosts es llamada subred de comunicación o simplemente subred. La subred transmite mensajes de host a host.
En las mayorías de WAN, la subred consiste de dos partes: lineas de transmisión y elementos de switching. Las lineas de transmisión mueve bits entre máquinas. Pueden ser de cobre, coaxial o fibra óptica. La mayoría de organizaciones no tienen lineas por ahí, por lo que utilizan las de compañías de telecomunicación. Los elementos de switching, también llamados routers, son dispositivos que conectan dos o más lineas de transmisión. Cuando los datos llegan de una linea entrante, el router debe elegir una linea de salida donde enviarlo.
En la mayoría de los WAN, la red contiene muchas lineas de transmisión, cada una conectando un par de routers. Dos routers que no comparten una linea de transmisión deben hacerlo mediante otro router. Hay muchos caminos que conectan estos dos routers. Cómo la red decide que camino usar se llama algoritmo de enrutamiento. Cómo cada router decide a dónde enviar un paquete a continuación es denominado algoritmo de reenvío.
,-----------------------------.
| |
+-------+ linea de +----------+
| Perth | O ------------- O | Brisbane |
+-------+ | transmision | +----------+
| | | |
| | | |
| | | | <- Subnet
| \ / |
| '---- O <- router |
| +-----------+ |
`------ | Melbourne | --------'
+-----------+
Protocolos de red
Para reducir la complejidad del diseño la mayoría de las redes se organizan como una pila de capas. Cada capa ofrece servicios a la capa superior mientras oculta los detalles de la implementación. Cuando dos capas (en diferentes hosts) se comunican entre sí utilizan un protocolo (forma en que se llevará a cabo la comunicación).
Para esto, los protocolos de red comparten objetivos en común, que incluye la fiabilidad, asignación de recursos, capacidad de evolución y seguridad.
Objetivo de diseño
Fiabilidad
La fiabilidad es el problema de diseño de hacer una red que opere correctamente a pesar de que está compuesto de componentes que por sí mismos no son confiables.
Un mecanismo para encontrar errores en información recibida es usar códigos de detección de errores. Información que es incorrectamente recibida puede ser retransmitida hasta que es recibida correctamente. Códigos más poderosos permiten corrección de errores, donde el mensaje correcto es recuperado de los bits incorrectos recibidos. Ambos mecanismos funcionan añadiendo información redundante. Son usados en capas inferiores, para proteger paquetes enviados sobre enlaces, y capas superiores, para verificar que la información recibida es correcta.
Otro problema de fiabilidad es encontrar un camino que funcione en una red. Generalmente existen múltiples caminos entre el origen y el destino, y en redes largas, puede haber enlaces o routers rotos. Este tópico se denomina enrutamiento.
Asignación de recursos
Un segundo problema de diseño son los recursos. Cuando las redes son amplias, nuevos problemas surgen. Diseños que continuan funcionando bien cuando la red se extiende se dice que es escalable. Las redes proveen servicios a los hosts utilizando sus recursos disponibles. Para eso, se necesitan mecanismos que dividan los recursos para que así un host no interfiera demasiado con otro.
Muchos diseños comparten banda de ancho dinámico, de acuerdo con las necesidades en corto plazo de los hosts, en vez de dar una parte fija. Esto se llama multiplexación estadística.
Otro problema que ocurre en todos los niveles es como mantener un emisor rápido de inundar a uno lento con datos. Cómo se soluciona es llamado control de flujo. Otras veces, el problema es que la red está sobresaturada porque muchas computadoras quieren enviar demasiado tráfico, y la red no puede manejarlo. Esta sobrecarga se llama congestión.
También es interesante observar que la red tiene más recursos que solo ancho de banda. Para usos como transmisión en vivo, el tiempo de entrega es importante. Por lo que muchas redes deben ser capaces también de entregar contenido en tiempo real. Calidad de servicio es el término usado para los mecanismos que resuelven estos problemas.
Evolución
Otro problema de diseño es la evolución de la red. Mientras pasa el tiempo, la red crece y nuevos diseños surgen que deben ser conectados a la red actual. Un ejemplo es el diseño de capas mencionado que oculta la implementación, el protocolo de capas.
Como hay muchas computadoras en la red, cada capa necesita un mecanismo capaz de identificar el emisor y receptor del mensaje. Este mecanismo es llamado direccionamiento.
Un aspecto del crecimiento es que diferentes tecnologías tienen limitaciones. Por ejemplo, no todos los canales conservan el orden de los mensajes, o el tamaño del mensaje excede el del canal. Esto lleva a mecanismos de desarmado, transmisión y reensamblado. Este tema se denomina interconexión.
Protocolo de capas
Para reducir la complejidad, las redes se organizan como una pila de capas o niveles, una encima de otra. El próposito de cada capa es ofrecer ciertos servicios mientras se esconde los detalles de la implementación.
Cuando una capa n en una máquina se comunica con la capa n de otra máquina, las reglas usadas son conocidas como el protocolo de la capa n. Es decir, un protocolo es un acuerdo entre las partes que se comunican en como debe realizarse la comunicación.
Las partes que comprenden las capas correspondientes en diferentes máquinas se denominan pares (peers). Los peers pueden ser procesos, dispositivos de hardware, o incluso humanos. En otras palabras, son los peers los que se comunican entre sí utilizando protocolos.
Host 1 Host 2
+--------+ Protocolo capa 5 +--------+
| Capa 5 | <------------------> | Capa 5 |
+--------+ +--------+
^ ^
| |
Interfaz capa 4/5 Interfaz capa 4/5
| |
v v
+--------+ Protocolo capa 4 +--------+
| Capa 4 | <------------------> | Capa 4 |
+--------+ +--------+
^ ^
| |
Interfaz capa 3/4 Interfaz capa 3/4
| |
v v
+--------+ Protocolo capa 3 +--------+
| Capa 3 | <------------------> | Capa 3 |
+--------+ +--------+
^ ^
| |
Interfaz capa 2/3 Interfaz capa 2/3
| |
v v
+--------+ Protocolo capa 2 +--------+
| Capa 2 | <------------------> | Capa 2 |
+--------+ +--------+
^ ^
| |
Interfaz capa 1/2 Interfaz capa 1/2
| |
v v
+--------+ Protocolo capa 1 +--------+
| Capa 1 | <------------------> | Capa 1 |
+--------+ +--------+
^ ^
| |
v v
+----------------------------------------+
| Medio físico |
+----------------------------------------+
En realidad, ningún dato es enviado directamente desde una capa a la otra. En cambio, cada capa pasa datos e información de control a la capa de abajo hasta que la última capa es alcanzada. Por debajo de todo se encuentra el medio físico donde la comunicación se realiza.
Entre cada capa adyacente existe una interfaz. La interfaz define las operaciones y servicios que la capa inferior ofrece a la capa superior. Además de minimizar la cantidad de información que debe pasarse entre capas, las interfaces hacen simple reemplazar una capa con otra implementación o protocolo.
Servicios vs protocolos
Servicios y protocolos son conceptos diferentes. Un servicio es el conjunto de primitivas (operaciones) que una capa provee a la capa superior. El servicio define que operaciones puede realizar la capa, pero no dice nada sobre los detalles de como la operación es realizada. Un servicio se relaciona con una interfaz entre dos capas, con la capa inferior siendo el proveedor de servicio y la capa superior el usuario del servicio. El servicio usa la capa inferior para permitir a la capa superior hacer su trabajo.
Un protocolo, por el otro lado, es un conjunto de reglas que definen el formato y significado de los paquetes, o mensajes que son intercambiados entre las entidades dentro de una capa. Las entidades usan los protocolos para implementar sus servicios. Ellos son libres de cambiar los protocolos, asegurando que el servicio visible a sus usuarios no cambia. En este sentido, los servicios y protocolos están completamente separados.
Capa k + 1 Capa k + 1
^ ^
| Servicio dado por capa k |
v v
+--------+ Protocolo +--------+
| Capa k | <------------------> | Capa k |
+--------+ +--------+
^ ^
| |
v v
Capa k - 1 Capa k - 1
Modelos de referencia
El diseño de protocolos de capas es una de las claves en la abstracción en el diseño de redes. Lo principal es definir la funcionalidad de cada capa y la interacción entre ellas. Dos modelos dominantes son el modelo TCP/IP y el modelo OSI.
El modelo OSI
Este modelo está basado en la propuesta de la International Standards Organization (OSI) como un primer paso en estandarizar los protocolos usados en las capas. Es llamado ISO OSI (Open Systems Interconnection) Reference Model porque se encarga de conectar sistemas abiertos, es decir sistemas abiertos a comunicarse con otros sistemas.

El modelo OSI tiene siete capas. Los principios que se aplicaron para llegar a siete capas es lo siguiente:
-
Una capa debe ser creada cuando se necesita una abstracción diferente.
-
Cada capa debe realizar una función bien definida.
-
La función de cada capa debe ser elegida considerando la definición de protocolos estandarizados.
-
Los límites de las capas deben ser elegidas para minimizar la información transmitida entre capas.
-
El número de capas debe ser lo suficientemente grande como para que funciones distintas no tengan que agruparse en la misma capa por necesidad y lo suficientemente pequeño como para que la arquitectura no se vuelva difícil de manejar.
Tres conceptos son centrales en el modelo OSI:
-
Servicios.
-
Interfaces.
-
Protocolos.
El modelo OSI hace esta distinción explícitamente. Cada capa ofrece un servicio para la capa superior. El servicio define que hace la capa, no como lo realiza.
El modelo TCP/IP
El modelo TCP/IP fue usado en el predecesor de todas las redes, el ARPANET, y es usado en su sucesor, Internet. El ARPANET fue una red de investigación patrocinado por el DoD (Department of Defense). Conectó cientos de universidades y gobiernos usando lineas telefónicas. Cuando se añadieron redes satelitales y de radio, los protocolos existentes tuvieron problemas para trabajar con ellas. Por lo que una nueva arquitectura era necesaria, una que tenga como objetivo conectar múltiples redes de manera fluida. Esta arquitectura luego se conoció como TCP/IP Reference Model, por sus dos protocolos principales.
Dada la preocupación del DoD de que un ataque de la Unión Soviética destruya los routers, hosts y enlaces de la red, otro objetivo de la arquitectura era la capacidad de sobrevivir al fallo de hardware sin cortar las comunicaciones. Es decir, se quería que las conexiones sigan intactas si el origen y destino estén funcionando. Para eso, se necesitaba una arquitectura flexible.
Capa de Enlace
La capa más baja, la capa de enlace, describe lo que deben hacer los enlaces, como las lineas serial y Ethernet. Realmente no es una capa en sí, sino más bien una interfaz entre los hosts y enlaces de transmisión.
Capa de Internet
La capa de internet es el eje que mantiene unida a toda la arquitectura. Su trabajo es permitir a los hosts inyectar paquetes en cualquier red y que estas puedan viajar independientemente a destino. Estos paquetes podrían llegar en cualquier orden, por lo que es el trabajo de las capas superiores reordenar.
OSI TCP/IP
+--------------+ +--------------+
7 | Aplicación | | Aplicación |
+--------------+ +--------------+
6 | Presentación | | | <------+
+--------------+ +--------------+ |
5 | Sesión | | | <------+
+--------------+ +--------------+ |
4 | Transporte | | Transporte | Ausentes
+--------------+ +--------------+ |
3 | Red | | Internet | |
+--------------+ +--------------+ |
2 | Enlace | | Enlace | |
+--------------+ +--------------+ |
1 | Física | | | <------+
+--------------+ +--------------+
La capa de internet define un formato oficial de paquetes y un protocolo llamado IP (Internet Protocol), además de un protocolo compañero llamado ICMP (Internet Control Message Protocol) que ayuda en su función. El trabajo de la capa de internet es entregar paquetes IP a donde se supone que tienen que ir. El enrutamiento de paquetes es un problema mayor aquí, como la congestión. El problema de enrutamiento está resuelto, pero la congestión solo puede ser resuelto por capas superiores.
Capa de Transporte
La capa por encima de la de internet es la capa de transporte. Esta diseñado en permitir a los peers llevar a cabo una conversación. Dos protocolos de fin-a-fin están definidos aquí. El primero, TCP (Transmission Control Protocol), es un protocolo orientada a la conexión confiable que permite que el flujo de bytes que sale de una máquina llegue a su destino sin errores. Segmenta el flujo de bytes en mensajes discretos y pasa cada uno a la capa de internet. En el destino, los paquetes son reensamblados nuevamente. TCP también controla el flujo de datos para asegurarse que un remitente rápido no inunde a un receptor lento con tantos mensajes.
El segundo protocolo es UDP (User Datagram Protocol), un protocolo no confiable orientado a sin conexión. Es usado para aplicaciones que no necesitan asegurar la llegada de paquetes en orden o control de flujo. También se utiliza ampliamente para consultas y aplicaciones de tipo cliente-servidor de solicitud-respuesta de un solo uso donde la rapidez de entrega es más importante que la calidad.
+-------------------------------+
Aplicación | HTTP SMTP RTP DNS |
+-------------------------------+
Transporte | TCP UDP |
+-------------------------------+
Internet | IP ICMP |
+-------------------------------+
Enlace | DSL SONET 802.11 Ethernet |
+-------------------------------+
Capa de Aplicación
Arriba de la capa de transporte está la capa de aplicación. Contiene todos los protocolos de alto nivel. Los primeros fueron terminales virtuales (TELNET), transferencia de archivos (FTP) y correos electrónicos (SMTP). Otros protocolos se fueron añadiendo con los años. Algunos importantes son el protocol de resolución de dominios (DNS), para asociar nombres de host a direcciones de red, HTTP, el protocolo para obtener páginas en la World Wide Web (WWW), y RTP, protocolo usado para entregar contenido en tiempo real como voz y video.
Capa física
El propósito de la capa física es transportar bits de una máquina a otra. Varios medios físicos pueden ser usados para la transmisión actual. Estos medios pueden ser guíados o cableados (cobre, cable coaxial, fibra óptica), no guíado o inalámbrico (radio terreste), y satélites. Cada una de esas tecnologías tienen diferentes propiedades que afectan el diseño y rendimiento de las redes que las usan.
Medio guíado de transmisión
La transmisión que depende de un cable físico o alambre son llamados medios guíados de transmisión porque su señal de transmisión son guíados por un camino en el cable físico o alambre. Las más comunes son los cables de cobre o la fibra óptica. Cada tipo de medio guíado viene con sus ventajas y desventajas en términos de frecuencia, ancho de banda, retraso, costo, y facilidad de instalación y mantenimiento. El ancho de banda es una medida de la capacidad de transporte de un medio. Está medida en Hz.
Almacenamiento persistente
La manera más común de transportar datos desde un dispositivo a otro es escribiéndolos en un almacenamiento persistente, como el almacenamiento mágnetico o de estado sólido, físicamente transportarlo a la máquina destino y volver a leer los datos. Aunque este método no es el más sofisticado, es a veces el más efectivo en costo, especialmente para aplicaciones donde una alta velocidad de datos o el costo por bit en un factor clave.
Par trenzado
Aunque el ancho de banda de los almacenamientos persistentes es excelente, no lo es tanto el retraso: la transmisión es medida en cuestión de horas o días, no milisegundos. Muchas aplicaciones, incluyendo la Web, dependen de la transmisión de datos con poco retraso. Uno de los métodos más viejos y comunes de medio de transmisión es el par trenzado. Un par trenzado consta de dos cables de cobre aislados. Los cables están trenzados entre sí similar al ADN. Este trenzado permite cancelar ruido externo en el medio de transmisión, ya que la señal se envía como la diferencia entre los dos niveles de voltaje y el ruido externo afecta a ambos por igual, dejando la diferencia casi sin cambios.
El par trenzado se puede utilizar para transmitir tanto información analógica o digital. El ancho de banda depende del grosor del cable y la distancia recorrida, pero se pueden lograr cientos de megabits/segundo en pocos kilómetros.
Los pares trenzados vienen en varias categorías. La más común, la categoría 5e, consiste en dos cables aislados ligeramente trenzados entre sí. Normalmente, se agrupan cuatro pares de este tipo en una funda de plástico para proteger los cables y mantenerlos juntos.
Diferentes LAN pueden usar los cables de diversas maneras. Enlaces que pueden ser usados en ambas direcciones al mismo tiempo, se dice que son full-duplex. En cambio, si puede ser usado en ambas direcciones, pero solo una dirección a la vez, es un enlace half-duplex. Una tercera categoría consiste del tráfico de una sola dirección. Estos son llamados simplex.
Cable coaxial
Otro medio común es el cable coaxial. Un cable coaxial consta de un alambre de cobre rígido como núcleo, rodeado por un material aislante. El aislante está recubierto por un conductor cilíndrico, a menudo en forma de malla trenzada de tejido tupido. El conductor exterior está recubierto por una funda protectora de plástico.
La construcción y protección del cable coaxial otorga una buena combinación de ancho de banda alta y protección contra el ruido. El ancho de banda que pueden tener es hasta 6 GHz, permitiendo múltiples conversaciones al mismo tiempo en un mismo cable. Los cables coaxial son utilizados para televisión por cable y redes metropolitanas, además de otorgar conexión de Internet.
Linea eléctrica
El uso de lineas eléctricas para la comunicación de datos es una idea vieja. Han sido usadas por compañías eléctricas para comunicaciones de baja frecuencia como la medición remota, como cotrolar dispositivos en el hogar.
La conveniencia de usar lineas eléctricas para redes debería ser claro. Enchufas una TV y un receptor, y ellos pueden enviar y recibir películas mediante la linea.
La dificultad de esto es que la linea eléctrica fue diseñada para transmitir señales de potencia. Esta tarea es distinta de transmitir señales de datos, el cual estos son terribles. La señal eléctrica viaja a unos 50-60 Hz y el cableado atenúa las frecuencias altas (MHz) que se necesitan para datos. Las propiedades eléctricas del cableado varían de casa en casa y cambian a medida que se apaguen y enciendan electrodomésticos, generando ruido. Además, el cableado puede actuar como antena, interceptando señales externas.
Fibra óptica
La fibra óptica es una tecnología de transmisión que usa pulsos de luz para enviar datos a través de delgadas hebras de vidrio extremadamente transparente. Su gran ventaja frente a los conductores de cobre es la enorme capacidad de ancho de banda, alcanzando velocidades de más de 100 Gbps y con pérdidas casi nulas, gracias a la reflexión interna total: un fenómeno físico que mantiene la luz confinada dentro del núcleo del cable. Dependiendo del diámetro del núcleo, existen fibras multimodo (más baratas, usadas en distancias cortas) y monomodo (más costosas, pero capaces de transmitir señales mucho más lejos sin amplificación). La luz usada proviene de LEDs o láseres y se detecta mediante fotodiodos, que convierten los pulsos luminosos en señales eléctricas.
El material base de la fibra es vidrio de alta pureza, con una atenuación mínima en longitudes de onda del infrarrojo (0.85, 1.30 y 1.55 micrones). Estas propiedades permiten enviar señales a grandes distancias con muy poca pérdida. Aunque la instalación de redes ópticas tiene un alto costo, especialmente en la “última milla” hacia los usuarios, su rendimiento supera ampliamente al de las tecnologías basadas en cobre. Gracias a avances como el uso de solitones y amplificadores ópticos, la fibra óptica constituye hoy la base de las redes troncales, conexiones de alta velocidad y enlaces internacionales, haciendo posible una comunicación de gran capacidad y fiabilidad.
Modos de transmisión
Cómo se mencionó anteriormente, los enlaces se pueden utilizar de diferentes maneras:
-
full-duplex: ambas direcciones al mismo tiempo.
-
half-duplex: ambas direcciones, pero solo una dirección a la vez.
-
simplex: permite solamente una única dirección.
simplex
+--------+ +----------+
| Emisor | --------------> | Receptor |
+--------+ +----------+
half-duplex
+--------+ <-------------- +----------+
| Emisor | O | Receptor |
+--------+ --------------> +----------+
full-duplex
+--------+ <-------------- +----------+
| Emisor | Y | Receptor |
+--------+ --------------> +----------+
Señales analógicas
Son generadas por por algún tipo de fenómeno electromagnético y son representables por una función en forma de onda.
El número de oscilaciones por segundo de una onda es su frecuencia, y se mide en Hertz (Hz). Es decir, 1 Hz = 1 ciclo por segundo.
En la naturaleza, el conjunto de señales que percibimos son analógicas, así la luz, el sonido, la energía etc., son señales que tienen una variación continua.
Señales digitales
Hasta ahora sabemos que las señales analógicas viajan por un medio de transmisión en forma de ondas electromagnéticas.
Queremos transmitir información binaria. Estos datos binarios van a ser codificados (o representados) con una señal analógica. De esta manera obtendremos una señal digital.
Modificando la frecuencia y la amplitud de las ondas y agregando armónicos (componentes de la señal) podemos obtener y transmitir un par de señales totalmente distinguibles llamadas señal "alta" y señal "baja".
Codificación y decodificación
Codificación es el proceso mediante el cual una señal digital (secuencia de bits: 0 y 1) se convierte en una señal analógica (una forma de onda continua en el tiempo) para poder ser transmitida a través de medios físicos que solo soportan señales analógicas, como cables eléctricos o el aire (en comunicaciones inalámbricas).
Decodificación es el proceso inverso: transformar una señal analógica recibida en su equivalente digital, recuperando los bits originales que representan la información transmitida.
Para esto se requieren de hardware capaz de realizar la codificación y decodificación de las señales.
Una placa de red (adaptador) es una pieza de hardware encargada de conectar un nodo de la red con el medio. Su tarea como emisor es codificar los bits en señales, y como receptor decodificar las señales en bits.
Para codificar y decodificar, se utilizan diferentes estrategias.
Codificación NRZ
La forma más directa de codificación es usar un valor de voltaje positivo para representar un bit 1 y un voltaje negativo para representar un bit 0. Este esquema se llama NRZ (Non-Return-to-Zero).
Una vez enviado, la señal NRZ se propaga por el cable. En el otro lado, el receptor convierte la señal en bits muestreando la señal en intervalos de tiempo.
El problema con NRZ, es que la representación de cada símbolo está determinado por su voltaje. Así, si se envían consecutivos 0s o 1s, se pierde precisión sobre la cantidad de símbolos. Enviar 16 ceros se vería similar a 15 si no se cuenta con algún reloj preciso.
Codificación Manchester
Un reloj preciso solucionaría los problemas, pero sería una solución costosa. Una estrategia es enviar una señal de reloj por separado al receptor. Otra linea no es un problema para los buses de computadora o cables cortos donde hay varios lineas en paralelo, pero para una red es derrochador, ya que gastaríamos una linea donde se podrían mandar datos para el reloj.
El truco es entonces mezclar la señal del reloj con la señal del dato haciendo XOR entre ellas, así no se utiliza una linea extra. El reloj hace una transición en cada tiempo de bit, por lo que funciona al doble del bit rate. Cuando se hace un XOR con un 0, hace una transición abajo hacia arriba que es el reloj. Esta transición es el 0. Cuando se hace XOR con 1, la señal se invierte y se realiza una transición arriba hacia abajo. Este esquema se llama codificación Manchester y fue usado para Ethernet.
Ancho de banda
El ancho de banda es una propiedad física del medio de transmisión que depende, por ejemplo, de la construcción, el grosor, la longitud y el material de un cable o fibra. Dependiendo de la señal, se habla de ancho de banda analógico o ancho de banda digital.
-
Ancho de banda analógico: Es el rango de frecuencia que se transmite sin una atenuación considerable. La señal se mide en Hertz (Hz). Indica la diferencia entre la frecuencia más alta y la más baja que puede pasar un canal.
-
Ancho de banda digital: El ancho de banda digital se refiere a la cantidad de datos que pueden transmitirse por segundo a través de un canal digital. Se mide en bits/segundo (bps).
Ruido en el canal
Otro aspecto a tener en cuenta durante la transmisión de señales es la presencia de ruido térmico (agitación de los electrones dentro del conductor). Este factor afecta el ancho de banda digital, en otras palabras, el ruido reduce el número máximo de bits/segundo.
Entropía
Los mensajes que se envían a traves de un canal de comunicación contienen información que se puede medir. Para eso se utiliza la entropía.
La entropía mide la cantidad promedio de información o incertidumbre contenida en una fuente de mensajes.
Sea un mensaje \(X\) que está escrito con un alfabeto de \(n\) símbolos (letras), y sea \(p(x_i) = \frac{\text{frecuencia de } x_i}{\text{longitud del mensaje}}\), la entropía se calcula de la siguiente forma:
La entropía también dice cual es el mínimo número de bits por símbolo necesarios en promedio para codificar el mensaje.
Codificación de Huffman
Hay que representar los mensajes en forma de bits. Cada carácter es representado con un código en bits. Si utilizamos el código ASCII representamos cada caracter con 7 bits. ¿Pero existe alguna manera de representar los caracteres con menos bits?
La codificación de Huffman es la codificación más eficiente en términos de espacio (garantizado por la entropía). Da como resultado un código prefijo (el código de un símbolo nunca es prefijo de otro código)
Su algoritmo es el siguiente:
-
Crear nodos para cada símbolo etiquetados con su frecuencia.
-
Unir los dos nodos de menor frecuencia en un nuevo nodo, etiquetar el nuevo nodo con la suma de las frecuencias.
-
Etiquetar las ramas con 0 y 1.
-
Repetir el paso 2 hasta obtener un solo árbol.
-
El código para un símbolo es el camino de bits desde la raíz hasta el símbolo.
Por la entropía se puede demostrar que se obtiene el código binario más eficiente. Se compara la entropía \(H(X)\) con la longitud promedio de \(L\).
-
Dado: \(P_i\) = probabilidad de ocurrencia de un símbolo.
-
Dado: \(L_i\) = longitud del código para representar ese símbolo.
-
Longitud promedio de todos los símbolos codificados: \(L = \sum_{i=0} P_i L_i\)
Si la longitud promedio del código está cerca de la entropía o es igual, entonces tu código es óptimo, no existe un código más chico (en cantidad de bits).
Muestreo
Hasta ahora se vio como enviar información. Pero ahora veremos cómo levantar esa información (en forma de señales) y convertirla en dígitos binarios.
La ténnica básica es el muestreo, que consiste en medir el valor de la señal en un determinado tiempo y guardar ese valor.
Si queremos reproducir la onda de manera completa podríamos tomar cuantas muestras queramos.
Muestreo de Nyquist
Nyquist establece que no es necesario tomar tantas muestras para replicar la señal. Si la frecuencia más alta es B, solamente alcanza con tomar muestras a una velocidad de 2B. Por ejemplo, si la señal tiene una frecuencia de 1 Hz, me alcanza con tomar muestras a frecuencias de 2 Hz.
Capa de enlace
La capa de enlace usa los servicios de la capa física para enviar y recibir bits sobre un canal de comunicación que puede perder datos.
Tiene un número de funciones que incluye:
-
Proveer un servicio bien definido a la capa de red.
-
Enmarcar secuencias de bytes en segmentos.
-
Detectar y corregir errores de transmisión.
-
Regular el flujo de datos para que receptores lentos no sean inundados por emisores rápidos.
Para cumplir este rol, la capa de enlace toma los paquetes de la capa de red y los encapsula en tramas (frames). Cada frame contiene un encabezado (header), campo de carga útil (payload field) donde guardar el paquete, y un terminador (trailer). La gestión de frames es el corazón de la capa de enlace.
Máquina Emisora Máquina Receptora
+---------+ +---------+
| Paquete | | Paquete |
+---------+ +---------+
| ^
v Frame |
+--------------------------+ +--------------------------+
| Head | Payload | Trailer | | Head | Payload | Trailer |
+--------------------------+ +--------------------------+
`-----------------------------------^
El problema de la asignación de canal
Asignar un solo de canal de difusión entre múltiples usuarios. El canal podría ser un espectro inalámbrico en una región geográfica, o un solo cable o fibra óptica en donde se conectan varios nodos.
+----+ Ethernet +----+ | PC | ------------ | PC | +----+ +----+ +----+ ---------. <------- Ethernet +----+ | PC | | | ,------- | PC | +----+ +--------------+ v +--------------+ +----+ +----+ | Switch / Hub | ------ | Switch / Hub | +----+ | PC | +--------------+ +--------------+ | PC | +----+ | `------- +----+ `-----------´
El canal conecta a cada usuario con todos los demás; cualquier usuario que utilice el canal interfiere con los demás que también desean usarlo.
Cuando dos terminales envían sus tramas al mismo tiempo puede ocurrir una colisión y la información de ambas se pierde.
Subcapa MAC y LLC
Los protocolos que se utilizan para determinar quién sigue en un canal multiacceso pertenecen a una subcapa de la capa de enlace de datos llamada subcapa MAC (Medium Access Control).
-
La MAC constituye la subcapa inferior de la capa de enlace de datos.
-
Se implementa mediante hardware, por lo general la NIC (Network Interface Card) de la PC.
-
Tiene dos responsabilidades principales:
-
Encapsulación de datos.
-
Control de acceso al medio.
-
En la subcapa LLC (Logical Link Control) se realiza la sincronización, se puede hacer control de flujo y en particular se realiza el chequeo de errores.
La LLC maneja la comunicación entre las capas superiores e inferiores. Toma los datos del protocolo de red y agrega información de control para ayudar a entregar el paquete a destino.
Protocolo CSMA
Protocolos en los que las estaciones escuchan si hay una transmisión y actúan de manera acorde son llamados carrier sense protocols. Se llaman así porque asegura que ninguna estación empezará a transmitir datos mientral el canal está ocupado.
Cuando una estación tiene datos que enviar, primero escucha el canal para ver si alguien está transmitiendo en ese momento. Si el canal está quieto, entonces la estación envía los datos. En caso contrario, si el canal está ocupado, la estación espera hasta que el canal esté quieto. Luego, la estación envía un frame. Si una colisión ocurre, la estación espera un tiempo aleatorio y empieza de nuevo.
El problema con este protocolo es que si dos estaciones están preparadas para enviar datos a la mitad de la transmisión de una tercera estación, ambas van a esperar hasta que la transmisión termine, y luego ambas al mismo tiempo enviarán los datos, generando una colisión.
Protocolo CSMA/CD
Aunque CSMA fue un avance con respecto a otros protocolos, si dos estaciones deciden transmitir al mismo tiempo, sus señales colisionan. Otra mejora es que las estaciones detecten rápidamente la colisión y corten la transmisión.
Este protocolo, llamado CSMA/CD (Carrier Sense Multiple Access with Collision Detection) es la base del Ethernet clásico. Es importante mencionar que la detección de errores es un proceso analógico. La estación emisora debe escuchar el canal mientras transmite. Si la señal recibida es diferente que la señal que envía, entonces sabe que una colisión ha ocurrido.
El tiempo para detectar una colisión es simplemente el tiempo que le toma a la señal de propagarse desde una estación a otra. Sea t el tiempo que tarda una trama en llegar al extremo más alejado de la red. Para evitar una colisión todas las tramas deberán tardar más de 2t de tal manera que la transmisión aún se esté llevando a cabo cuando la ráfaga de ruido regrese al emisor.
Ejemplo: LAN de 10 Mbps de longitud máxima de 2500 metros. El tiempo de ida y vuelta es de 50 micro segundos. ¿Qué tamaño debe tener la trama?
1 000 000 microsegundos -> 1 segundo -> 10 Mbits -> 10 * 1 000 000 bits 50 microsegundos ---------------------------------> 500 bits (se redondea a potencia de 2: 2^9 = 512 bits = 64 bytes)
Hub vs Switch
La clave para entender estos dispositivos es que operan en diferentes capas. La capa importa porque cada dispositivo usa diferentes piezas de información para decidir cambiar.
Un hub tiene un número de lineas de entrada que se unen eléctricamente. Las tramas llegan en cualquiera de las lineas y son enviadas a todas las demás. Los hubs son dispositivos de la capa física, y no examinan ni usan las direcciones de la capa de enlace. En una red Ethernet con hubs, los hosts comparten un solo canal concentrado en el hub.
En la capa de enlace encontramos los bridges. Switches son bridges modernos con otros nombres. Un bridge (puente) conecta dos o más LAN. Como un hub, un bridge moderno tiene varios puertos, normalmente suficientes para entre 4 y 48 líneas de entrada de un tipo determinado. Cuando llega un frame, el bridge extrae la dirección de destino del encabezado y la busca en una tabla para ver dónde enviarla. En el caso de Ethernet, esta dirección es la dirección de destino de 48 bits (MAC). El bridge solo envía la trama al puerto donde se necesita y puede reenviar varias tramas al mismo tiempo. En una red Ethernet con switches, cada host se comunica con un switch, que a su vez reenvía ese tráfico sólo al host destino.
puerto puerto
| |
v +-----------+ v +------------+
--------- O | ---+ | --------- O | o--o--o--o |
| | | | | | | | |
--------- O | ---+ | --------- O | o--o--o--o |
| +----o | | | | | | |
--------- O | ---+ | --------- O | o--o--o--o |
| | | | | | | | |
--------- O | ---+ | --------- O | o--o--o--o |
^ +-----------+ ^ +------------+
| Hub | Switch
linea linea
En una red Ethernet con switches, el dominio de colisión se reduce a la conexión entre el host y el switch. Además, el estándar 10BASE-T introdujo un modo de operación full-duplex que se hizo común con Fast Ethernet y el estándar de facto con Gigabit Ethernet. En full-duplex, el switch y host pueden enviar y recibir simultáneamente, y por lo tanto están libres de colisiones.
Ethernet y CSMA/CD
Ethernet utiliza CSMA/CD 1-persistente. Se llama 1-persistente porque al detectar colisión espera un tiempo aleatorio antes de empezar de nuevo. La estación transmite con una probabilidad de 1 cuándo encuentra el canal quieto, de ahí su nombre.
Formato de la trama en 802.3
Primero viene un preámbulo de 8 bytes, cada uno de los cuales contiene el patrón de bits 10101010 (con la excepción del último byte, en que los dos últimos bits se establecen en 11).
Este último byte se llama delimitador de inicio de trama en el 802.3. La codificación de Manchester de este patrón permite que el reloj del receptor se sincronice con el del emisor.
Los dos últimos bits (SOF - Start of Frame) indican al receptor que está a punto de empezar el resto de la trama.
Después vienen dos direcciones, una para el destino y otro para el origen. Cada una tiene una longitud de 6 bytes.
El campo final es la suma de verificación (checksum). Es un CRC (Cyclic Redundancy Check) de 32 bits y sirve como código de detección de errores que se utiliza para determinar si los bits de la trama se recibieron correctamente. Solo realiza detección de errores y la trama se desecha si se detecta uno.
+----------------------------------------------------------------+ | Pre. | SOF | Dest. | Orig. | Long. | Data | Relleno | Checksum | +----------------------------------------------------------------+
Ethernet y MAC
Las direcciones MAC son asignadas por la IEEE de manera central para asegurar que no haya dos estaciones en el mundo con la misma dirección.
Una dirección MAC se escribe como una secuencia de 6 números hexadecimales, cada número corresponde a 1 byte.
Ejemplo: 8:0:2b:e4:b1:2 es la representación en hexadecimal de la dirección Ethernet 00001000 00000000 00101011 11100100 10110001 00000010
Otro uso de la dirección MAC está relacionado con la seguridad. Se crea una whitelist de direcciones MAC permitidas. Cuando se conecta un hardware que no está en la lista, no tendrá conexión.
Wireless LAN y protocolo CSMA/CA
En una red wireless, las conexiones son inalámbricas. El adaptador de red está diseñado para emitir señales electromagnéticas que son captadas por un dispositivo que concentra la comunicación, como un switch, pero que en este caso se llama access point (AP) o punto de acceso.
Una configuración común para una LAN wireless es la oficina de un edificio con AP puestos alrededor del edificio. Los AP están cableados juntos mediante cobre o fibra, y proveen conectividad a todas las estaciones que hablen con ellas.
Un problema con las redes wireless es que son incapaces de detectar colisiones, ya que la señal recibida puede ser muy pequeña, quizás millones de veces más que la señal transmitida.
Por eso, una estrategia en las LAN wireless es usar CSMA: escuchar si alguien está transmitiendo y transmitir cuando nadie lo hace. El problema es que, antes de empezar la transmisión, una estación realmente quiere saber si hay actividad de radio alrededor del receptor. CSMA simplemente avisa si hay actividad cerca del transmisor. Con cables, todas las señales se propogan a todas las estaciones, pero una sola transmisión a la vez puede tomar lugar en el sistema. En un sistema de ondas cortas de radio, múltiples transmisiones ocurren en simúltaneo si todas tienen diferentes destinatarios.
Para solucionar ese problema, se emplea el protocol CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance). 802.11 en vez de detectar colisiones, intenta evadirlas. La estación espera hasta que el canal está inactivo, para lo cual detecta que no hay señal durante un período corto de tiempo y realiza un conteo descendente (retroceso o backoff), haciendo pausa cuando se envían tramas. Envía su trama cuando el contador llega a 0. Si el frame llega a destino, el receptor inmediatamente envía un breve acknowledgement. La falta de esta confirmación indica que hubo un error, sea por colisión o algo más. En ese caso, el emisor incrementa el backoff e intenta de nuevo, hasta que la trama finalmente llega a destino o el máximo de intentos se ha alcanzado.
Para saber cuándo el canal está activo, cada trama lleva un campo NAV (Network Allocation Value) que indica cuánto tiempo tardará la trama. Las estaciones que escuchen esta trama saben que el canal estará ocupado durante el período de tiempo indicado por el NAV.
Capa de red
La capa de red se ocupa de que los paquetes enviados por el origen lleguen a destino. Llegar a destino puede requerir varios saltos a través de routers intermedios por el camino. Esta funcionalidad contrasta con la capa de enlace, que tiene el objetivo más modesto de transmitir frames de un punto a otro mediante un "cable" virtual. Por lo que la capa de red es la capa más baja que lidia con comunicación de fin-a-fin.
La capa de red debe conocer la topología del sistema (enrutadores y enlaces) y calcular rutas eficientes, evitando la sobrecarga de algunos enlaces mientras otros quedan inactivos. Cuando conecta redes autónomas, surgen desafíos adicionales como coordinar el tráfico y gestionar el uso de recursos. Antes, los operadores configuraban la red manualmente, pero con las redes definidas por software y el hardware programable, ahora es posible hacerlo mediante software de alto nivel e incluso redefinir las funciones de la capa de red.
Problemas de diseño de red
Conmutación de paquetes con almacenamiento y reenvío
La red está compuesta por el equipo del proveedor de servicios (routers, switches y otros dispositivos interconectados) y por el equipo de los clientes. Un host puede conectarse directamente al enrutador del proveedor, como en una conexión doméstica, o mediante una red local con su propio enrutador que enlaza con el del proveedor.
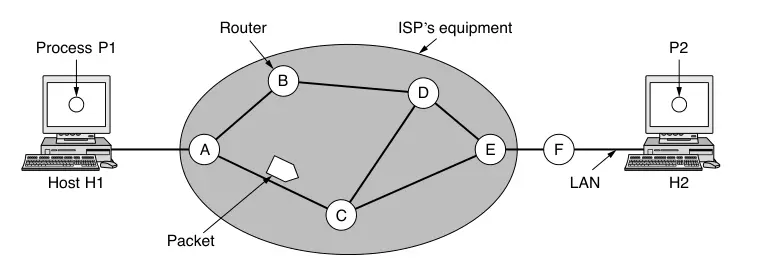
Un host con un paquete para enviar lo transmite a su router más cercano. El paquete es almacenado ahí hasta que llegue por completo y el enlace termine de procesar verificando el checksum. Luego es reenviado al siguiente router en el camino hasta que llega al host destino. Este mecanismo se llama store-and-forward packet switching (conmutación de paquetes con almacenamiento y reenvío).
Servicios prestados a la capa de transporte
La capa de red provee servicios a la capa de transporte. Los servicios deben ser diseñados con los siguientes objetivos:
-
Los servicios deben ser independientes de la tecnología del router.
-
La capa de transporte debe estar protegida del número, tipo y topología de los routers presentes.
-
Las direcciones de red disponibles a la capa de transporte deben usar un plan de numeración uniforme incluso entre LANs y WANs.
Dado esos goles, se tiene mucha libertad al diseñar la cada de red. Esta libertad dio pie a dos principales puntos de vista: el servicio de red debe ser orientada a la conexión o debe ser sin conexión.
Un campo argumenta que los routers deben mover paquetes y nada más. Por lo que la red es inherentemente desconfiable y los hosts deben realizar chequeos de errores y control de flujo. El servicio debe ser connectionless (no conexión), con primitivas SEND PACKET y RECEIVE PACKET y nada más. Este razonamiento es un ejemplo del argumento fin-a-fin, un diseño influyente en dar forma a Internet. Por lo que cada paquete debe contener la dirección destino completa, ya que cada paquete se transporta independientemente de sus predecesores.
Otro campo argumenta que la red debe proveer un servicio confiable orientado a la conexión. Este punto de vista afirma que la calidad del servicio es el factor importante, y sin conexiones en la red, la calidad de servicio es difícil de lograr.
Implementación de servicios sin conexión
En servicios sin conexión, los paquetes son inyectados a la red individualmente y ruteados independientemente de cada uno. En este contexto, los paquetes son llamados datagrams (datagramas) y la red es llamada datagram network (red de datagramas).
Veamos un ejemplo. El proceso P1 tiene un mensaje largo para P2. El protocolo de la capa de transporte funciona en H1, típicamente con el SO. Le antepone una cabecera de transporte y se lo entrega a la capa de red.
Supongamos que el mensaje es 4 veces más grande que el tamaño máximo de paquete, por lo que la capa de red lo rompe en 4 paquetes y los envía al router A. En este punto el ISP toma control. Cada router tiene una tabla interna que dice a dónde enviar paquetes por cada posible destinatario. Cada entrada de la tabla consiste en un par con el destino y la línea de salida a usar para ese destino. Solo lineas directamente conectadas pueden ser usadas.
En A, los tres primeros paquetes son guardados brevemente. Luego, cada paquete es reenviado de acuerdo con la tabla de A, hacia el enlace saliente a C dentro de un nuevo frame. El paquete 1 es reenvíado a E y luego a F. Cuando llega a F, se envía dentro de un frame a través de la LAN a H2. Los paquetes 2 y 3 siguen la misma ruta.
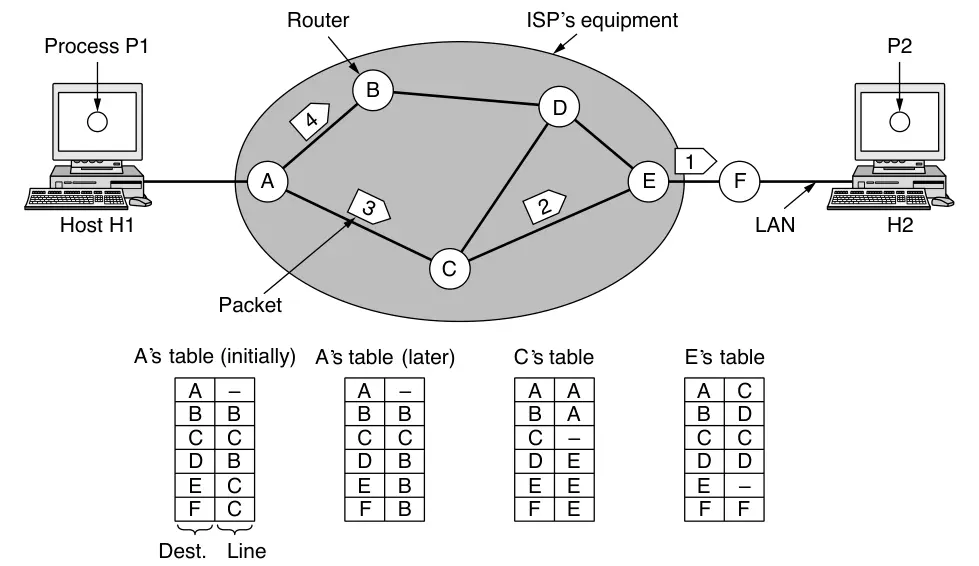
Sin embargo, sucede algo diferent en el paquete 4. Cuando llega a A, se envíá a B, incluso si su destino es F. Por alguna razón, quizás hay congestión por la otra linea, decidió enviarlo por otra ruta, actualizando su tabla de rutas. El algoritmo que gestiona las tablas y toma las decisiones de ruta es llamado routing algorithm (algoritmo de enrutamiento).
IP, la base de Internet, es un ejemplo de un servicio de red sin conexión. Cada paquete contiene la dirección IP destino que los routers usan para reenviar individualmente cada paquete.
Implementación de servicios con conexión
Para servicios orientados a la conexión, se necesita una virtual-circuit network (red de circuito virtual). Una VC (Virtual Circuit) es una conexión hasta el router destino que se establece antes de enviar cualquier paquete. La idea es evitar elegir nuevas rutas por cada paquete enviado. En cambio, cuando se establece una conexión, una ruta desde la máquina origen a la máquina destino es elegida como parte de la conexión y guardado en tablas dentro del router. Esa ruta es usada para todo el tráfico de esa conexión. Cuando la conexión se libera, el VA también finaliza. Con este tipo de servicio, cada paquete contiene un identificador indicando en que VA pertenecen.

Ejemplo: host H1 estableció conexión 1 con H2. Esta conexión es guardada como la primera en cada tabla de ruteo. La primera linea dice que si un paquete con conexión 1 llega desde H1, debe ser enviado a C y darle identificación de conexión 1. Similarmente, la primera entrada de C rutea el paquete hacia E, también con conexión 1.
Si ahora H3 quiere establecer conexión con H2, elige como identificador 1, porque es la primera y única conexión hasta ahora y le dice a la red que quiere establecer la VA. Ahora tenemos un conflicto, porque aunque A puede distinguir las conexiones, C no puede. Por esa razón, A le da un nuevo identificación a la salida hacia C. Evitar conflictos de este tipo es el motivo de por qué routers deben poder reemplazar identificadores de conexión de paquetes salientes.
Un ejemplo de estas conexiones son las MPLS (MultiProtocol Label Switching). Es usado por los ISP en el Internet, con paquetes IP encapsulados en cabeceras de 20 bits MPLS con el identificador de conexión.
Algoritmos de enrutamiento
Un algoritmo de enrutamiento (algorithm routing) es la parte del software de la capa de red que se encarga de decidir por cuál linea de salida un paquete entrante debe ser transmitido.
Si el protocolo utiliza datagramas internamente, la decisión del routing debe ser decidida de nuevo por cada paquete que llega, ya que la mejor ruta puede haber cambiado desde la última vez.
Si el protocolo utiliza VA, las decisiones de ruteo solo son hechas cuando una nueva VA está siendo configurado. Por lo tanto, los paquetes de datos solo siguen la ruta establecida. Este caso es llamado session routing (sesión de enrutamiento) porque la ruta permanece por la sesión entera (por ejemplo, una VPN).
Es útil hacer una distinción entre enrutamiento (routing), y reenvío (forwarding):
-
routing: la decisión sobre cuál ruta usar al reenviar paquetes. Mediante algoritmos de enrutamiento se actualizan las tablas de rutas.
-
forwarding: ver cuál ruta debe usarse para enviar un paquete entrante.
Algoritmos de enrutamiento pueden ser agrupados en dos tipos:
-
No adaptativos: no basan sus decisiones de ruteo en mediciones o estimaciones de la topología y tráfico. En cambio, la elección de una ruta a usar para ir de I a J es computada por adelantado, offline y descargado en los routers. Este procedimiento es llamado también enrutamiento estático. Como no responde a fallos, es útil cuando la ruta es clara. Un ejemplo es definir un default gateway.
-
Adaptativos: cambian sus decisiones de rutas para reflejar cambios en la topología y tráfico de la red. Estos algoritmos dinámicos de enrutamiento difieren en dónde obtienen la información (localidad, routers adyacentes, o de todos los routers), cuándo cambian las rutas (la topología cambia, o cada ciertos segundos) y cuál métrica es usada para optimización (distancia, números de saltos, tiempo estimado de tránsito).
Inundación
Cuando un algoritmo de enrutamiento es implementado, cada ruta hace una decisión en base a conocimiento local, no la red completa. Una técnica local simple es la de inundamiento (flooding), en la cual cada paquete entrante es enviado a cada linea de salida excepto por la cual llegó.
La inundación obviamente genera un número vasto de paquetes duplicados, incluso infinitos si no se cuenta con medidas para evitarlo. Un método es tener un contador de saltos contenido en el header de cada paquete que es decrementado en cada salto, y descartado cuando el contador llega a cero.
Inundar con un contador de saltos puede producir un número exponencial de paquetes duplicados a medida que el contador de saltos crece y routers duplican paquetes que ya han visto. Una mejor técnica es que los routers mantengan un seguimiento de los paquetes inundados, para evitar mandarlos una segunda vez. Una forma de lograr esto es que el router origen ponga un número de secuencia en cada paquete que recibe de sus hosts. Cada router necesita una lista por router de origen que indique qué indique que números ya se han visto. Si un paquete está en la lista, no se inunda.
Inundar no es práctico para mandar la mayoría de paquetes, pero tiene usos importantes.
Primero, asegura que un paquete haya llegado a cada nodo de la red. Es un desperdicio si solo hay un destinatario, pero es efectivo para el broadcasting.
Segundo, la inundación es extremedamente robusta. Incluso si un número amplio de routers explotan en mil pedazos, la inundación encontrará un camino si existe al destino. Además, requiere poca configuración: los routers solo deben conocer sus vecinos. Es decir, que la inundación puede ser usado para construir otros algoritmos de enrutamiento más eficientes pero necesitan más configuración.
Vector distancia
El algoritmo de enrutamiento de vector distancia (distance vector routing) hace que cada router mantenga una tabla con la mejor distancia conocida a cada destino y el enlace que se puede usar para llegar ahí. Estas tablas son actualizadas intercambiando información con los vecinos. Eventualmente, cada router sabe el mejor enlace para llegar a destino.
Este algoritmo es también conocido como el algoritmo de enrutamiento de Bellman-Ford distribuido, por los investigadores que la diseñaron. Fue el enrutamiento original del ARPANET y fue usado por Internet bajo el nombre de RIP.
Cada router mantiene una tabla de ruteo indexada por, y conteniendo una entrada de, cada router en la red. Esta entrada tiene dos partes: la linea de salida preferida para ese destino, y la estimación de la distancia a ese destino. La distancia puede ser el número de saltos o alguna otra métrica como el delay.
Un ejemplo:
-
Al principio nadie sabe la distancia al router A, por eso ponen infinito en su tabla de ruteo.
-
En el segundo paso, el router B detecta que A está a un salto.
-
En el tercer paso, la información de B se transmite al router C y así sucesivamente.
Paso 1:
A B C D E
o---o---o---o---o
- - - -
Paso 2:
A B C D E
o---o---o---o---o
- - - -
1 - - -
Paso 3:
A B C D E
o---o---o---o---o
- - - -
1 - - -
1 2 - -
El problema del conteo-a-infinito
El establecimiento de las rutas óptimas a través de la red se denomina convergencia. Vector distancia es útil como una técnica simple la cual routers pueden colectivamente computar caminos cortos, pero tiene problemas en la práctica: aunque converja a una respuesta correcta, lo hace lento. Reacciona rápidamente a buenas noticias, pero lento a las malas.
Cuando el router A se activa, los demás lo descubren mediante intercambios de vectores. En el primer intercambio, B detecta que A tiene un retraso cero y lo registra como un salto de distancia. Luego, en el siguiente intercambio, C aprende de B que A está a un salto y actualiza su tabla con una distancia de dos saltos. Los routers restantes lo sabrán más tarde. Así, la información sobre la disponibilidad de A se propaga un salto por intercambio. En una red donde el camino más largo es de N saltos, en N intercambios todos sabrán acerca de nuevos routers encendidos.
Ahora, supongamos que A se desconecta y el enlace de A a B es cortada. En el primer intercambio, B no escucha nada de A. Por fortuna, C avisa que tiene un salto de 2 hacia A. B no puede sospechar que C llega a A a través de B. Para B, C puede contener múltiples cáminos hacia A de salto 2.
Como resultado, B piensa que puede llegar a A mediante C con 3 saltos. En el segundo intercambio, C se da cuenta que sus vecinos dicen que tienen un camino a A de 3, por lo que elige uno aleatorio y actualiza su distancia a A a 4.
Las malas noticias se propagan lentamente porque cada router solo aumenta su valor un punto por encima del mínimo de sus vecinos. Todos terminan alcanzando el valor de infinito, pero la cantidad de intercambios depende del número elegido para representarlo; por eso conviene fijar infinito como la longitud del camino más largo más uno.
Estado de enlace
Vector distancia fue usado en el ARPANET hasta 1979, cuando fue reemplazado por el enrutamiento de estado de enlace. El principal problema que causó su ruina fue que tardaba mucho en converger después de que la topología de la red cambiara (debido al conteo-a-infinito). Por consecuencia, fue reemplazado por un nuevo algoritmo llamado enrutamiento de estado de enlace (link state routing). Variantes de este algoritmo llamados IS-IS (Intermediate System to Intermediate System) y OSPF (Open Shortest Path First) son usados ampliamente en redes largas e Internet.
La idea tras el enrutamiento de estado de enlace es simple y puede ser resumido en 5 partes. Cada router debe hacer lo siguiente para que funcione:
-
Descubrir sus vecinos y aprender sus direcciones de red.
-
Establece la distancia o la métrica de costo para cada uno de sus vecinos.
-
Construir un paquete contándole a todos lo que aprendió.
-
Enviar este paquete hacia y recibir paquetes de todos los routers.
-
Computar el camino más corto hacia cada otro router.
En efecto, la topología completa es distribuida a cada router. Luego algoritmos de camino corto (como Dijkstra) pueden ser ejecutados en cada router para encontrar el camino más corto hacia otro router.
Gestión de tráfico
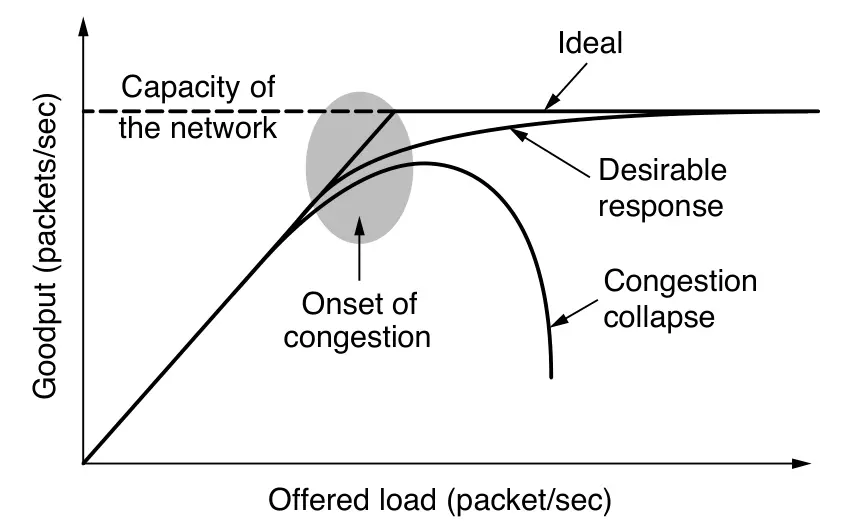
Muchos paquetes en cualquier parte de la red pueden introducir delay y pérdida causando degradamiento en el rendimiento. Esta situación se llama congestión.
Las capas de red y de transporte comparten la responsabilidad de manejar la congestión. Como la gestión ocurre en la red, es la capa de red que directamente lo experimenta y debe determinar qué hacer con el exceso de paquetes.
Enrutamiento consciente de tráfico
El enrutamiento consciente del tráfico busca ajustar las rutas según la carga de la red, desviando el tráfico de los enlaces congestionados. Para ello, el peso de cada enlace se calcula considerando su ancho de banda, retardo de propagación y carga actual.
Sin embargo, este método puede provocar oscilaciones: cuando un enlace se sobrecarga, el tráfico se desvía a otro, que luego también se satura, y el proceso se repite.
Dos soluciones comunes son el enrutamiento multipath (usar varias rutas en paralelo) y realizar los ajustes lentamente para permitir la convergencia.
Por estas dificultades, Internet no adapta sus rutas automáticamente al tráfico; en cambio, los operadores ajustan parámetros manualmente mediante ingeniería de tráfico. Hoy en día, tecnologías como las redes definidas por software (SDN) y MPLS permiten automatizar y optimizar parte de este proceso.
Regulación de tráfico
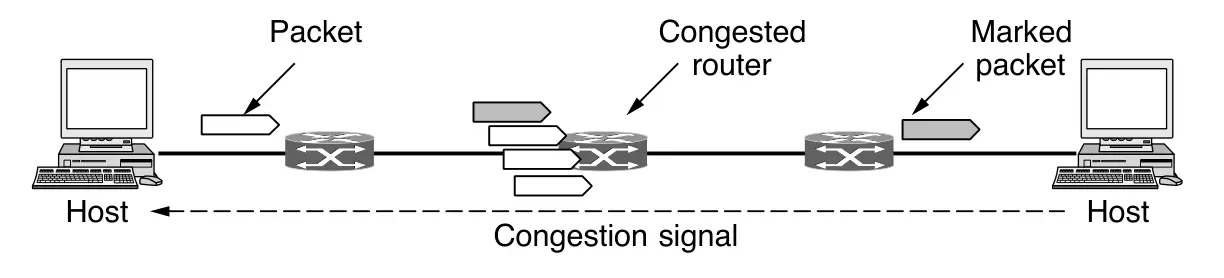
En lugar de generar paquetes adicionales para advertir sobre la congestión, un enrutador puede marcar cualquier paquete que reenvíe (estableciendo un bit en el encabezado del paquete) para señalar que está experimentando congestión. De esta forma, los emisores ajustan sus transmisiones para enviar tanto tráfico como la red pueda manejar sin saturarse.
Cuando la red entrega el paquete, el destino puede detectar la marca de congestión e informar al emisor en su siguiente paquete de respuesta. El emisor, al recibir esta notificación explícita de congestión, reduce su tasa de transmisión, de forma similar a como lo haría al recibir paquetes de estrangulamiento (choke packets).
Este diseño, conocido como ECN (Explicit Congestion Notification), se utiliza actualmente en Internet (Ramakrishnan et al., 2001) y es una mejora de los primeros protocolos de señalización de congestión, en particular del esquema de retroalimentación binaria de Ramakrishnan y Jain (1988) empleado en la arquitectura DECnet.
ECN utiliza dos bits en el encabezado IP para indicar si un paquete ha experimentado congestión. Los paquetes se envían inicialmente sin marcar; si alguno de los enrutadores por los que pasa el paquete está congestionado, marcará el paquete antes de reenviarlo. Posteriormente, el destino reflejará esas marcas al emisor como una señal explícita de congestión a nivel superior (por ejemplo, en TCP), permitiendo así un control eficiente del tráfico sin necesidad de descartar paquetes.
Desprendimiento de carga
Cuando ninguno de los métodos hace desaparecer la congestión, routers pueden sacar la artillería pesada: el desprendimiendo de carga (load shedding). Esta es una manera agradable de decir que cuando los routers son inundados con paquetes que no pueden procesar, simplemente los tiran.
La cuestión es qué paquetes tirar. Esto dependerá del tipo de aplicación que se esté usando en la red. Para la transferencia de archivos, se prefieren los paquetes viejos, ya que descartar paquetes nuevos hará solamente que el receptor haga más trabajo en mantener el buffer de datos que todavía no puede procesar. Pero en cambio, en medios de tiempo real, paquetes nuevos son preferibles, ya que paquetes que son retrasados se vuelven inútiles para cuando se necesitan.
La política de "lo viejo es mejor que lo nuevo" se denomina vino (wine) y la política de "lo nuevo es mejor que lo viejo" se denomina milk (leche).
Interconexión
Hasta ahora, se asumió que las redes son homogéneas, con cada máquina usando los mismos protocolos en cada capa. Lamentablemente, este pensamiento es muy optimista. Muchas redes existen, incluyendo las redes PAN, LAN, MAN, y WAN. Existe Ethernet, Internet, 802.11, como otros. Numerosos protocolos están en amplio en las redes en cada capa.
Cuando los paquetes enviados desde un origen en una red deben transitar una o más redes extranjeras antes de llegar a la máquina objetivo, pueden surgir muchos problemas en las interfaces entre redes.
| Aspecto | Posibilidades |
|---|---|
|
Servicio ofrecido |
Sin conexión vs. orientado a conexión |
|
Direccionamiento |
Distintos tamaños, plano o jerárquico |
|
Difusión |
Presente o ausente |
|
Tamaño de paquete |
Cada red tiene su propio valor máximo |
|
Ordenamiento |
Entrega ordenada y desordenada |
|
Calidad del servicio |
Presente o ausente: muchos tipos distintos |
|
Confiabilidad |
Distintos niveles de pérdida |
|
Seguridad |
Reglas de privacidad, cifrado, etc |
|
Parámetros |
Distintos tiempos de expiración, especificaciones de flujo, etc |
|
Contabilidad |
Por tiempo de conexión, paquete, byte o ninguna |
Surge un problema de interconexión cuando un paquete grande quiere viajar a través de una red cuyo tamaño máximo de paquetes es muy pequeño.
Una solución es asegurarse que el problema no ocurra en primer lugar. Esto obviamente es más fácil decirlo que hacerlo. El origen no sabe la ruta que tomará un paquete a través de la red hacia un destino, por lo que en definitiva no sabe qué tan pequeños deben ser los paquetes para llegar ahí. Este tamaño de paquete es llamado Path MTU (Path Maximum Transmission Unit) o MTU de la ruta. Incluso si el origen conociera la MTU de la ruta, los paquetes se enrutan de forma independiente en una red sin conexión como Internet. Este enrutamiento significa que las rutas pueden cambiar repentinamente, lo que puede modificar de forma inesperada la MTU de la ruta. Por lo tanto, la MTU de la ruta es un valor que depende de la red y no del paquete.
La solución alternativa al problema es permitir que los routers puedan romper los paquetes en fragmentos, enviando cada fragmento como un paquete separado. El problema es que es más fácil romper los paquetes que volver a juntarlos.
Existen dos estrategias opuestas para recombinar fragmentos de un paquete:
-
Fragmentación transparente: Los fragmentos se reensamblan en el router de salida del subred de paquetes pequeños, de modo que las redes posteriores no notan la fragmentación. Es simple, pero tiene desventajas: el router debe almacenar y esperar todos los fragmentos, usar campos especiales para saber cuándo llegó el último, y todos los fragmentos deben seguir la misma ruta, lo que limita el rendimiento. Además, si el paquete pasa por varias redes pequeñas, debe fragmentarse y reensamblarse repetidamente, aumentando la carga.
-
Fragmentación no transparente: Los fragmentos no se reensamblan hasta el destino final; cada uno se trata como un paquete independiente. Este método, usado por IP, reduce el trabajo de los routers. Cada fragmento lleva un número de paquete, un desplazamiento y una marca de fin, lo que permite reconstruir el mensaje incluso si los fragmentos llegan fuera de orden o se vuelven a fragmentar.
Aunque más eficiente para los routers, este método aumenta la sobrecarga de encabezados y tiene un problema mayor: si un fragmento se pierde, se pierde todo el paquete, lo que degrada el rendimiento general.
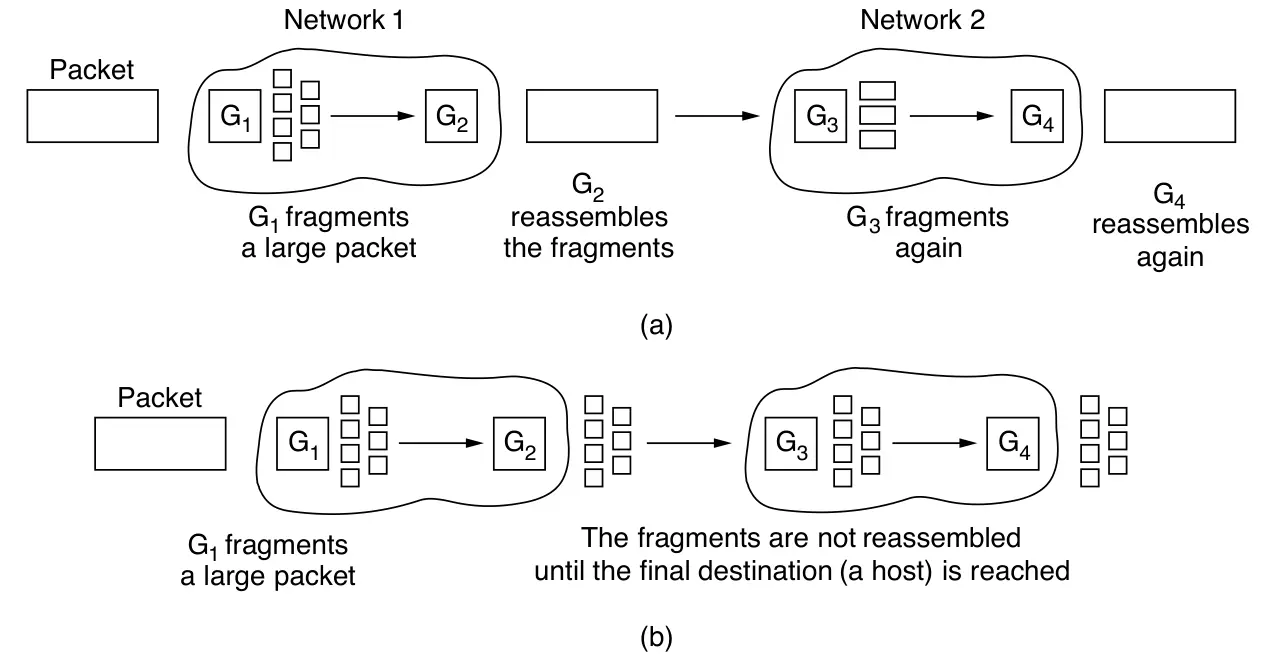
Esto nos lleva de nuevo a la solución original de no fragmentar paquetes. Este proceso es llamado path MTU discovery (descubrimiento de la MTU de ruta). La manera en la que funciona es así: cada paquete IP es enviado con sus bits de cabecera indicando que no quieren ser fragmentados. Si el router recibe un paquete demasiado grande, genera un paquete de error, lo devuelva al origen y descarta el paquete. Cuando el origen recibe el paquete de error, usa la información dentro para refragmentar el paquete en piezas más pequeñas suficientemente chicas para que el router pueda manejarlas. Si un router más lejos en el camino tiene un MTU más chico, el proceso es repetido.
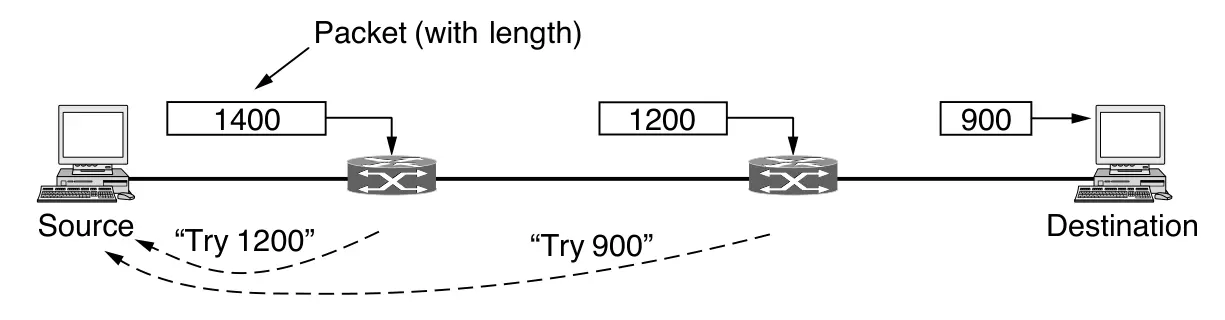
La detección de la MTU del trayecto (Path MTU Discovery) permite que el origen conozca el tamaño máximo de paquete que puede enviar sin fragmentación. Si la ruta cambia, los nuevos errores informan al origen para que se adapte. Este método reduce la fragmentación en la red, trasladándola a los hosts, especialmente cuando TCP e IP cooperan para ajustar el tamaño de los datos enviados.
Su desventaja es el retraso inicial, ya que pueden requerirse varios intercambios antes de enviar datos útiles. Se ha propuesto un diseño alternativo donde cada router trunca los paquetes que exceden su MTU, permitiendo al destino descubrirla más rápido al recibir parte de los datos.
La capa de red en el Internet
Estos son los principios que diseñaron a Internet y lo hicieron tan exitoso. Estos principios están enumerados y discutidos en RFC 1958. Esta es la lista de los 10 principios más importantes:
-
Aségurate que funcione: No finalices el diseño o estándar hasta que múltiples prototipos se hayan comunicado con cada uno.
-
Mantenlo simple (KISS): ante la duda, usa la solución más simple. Si una funcionalidad no es necesaria, déjala, en especial cuando se puede lograr el mismo efecto combinando otras funcionalidades.
-
Haz elecciones claras: si hay muchas maneras de hacer las cosas, elige una. Tener una o más maneras de hacer las cosas es buscar problemas.
-
Explota la modularidad: este principio lleva a la idea de tener pilas de protocolos, cada una de cuyas capas es independiente de todas las demás.
-
Espera heterogeneidad: en cualquier red grande se darán diferentes tipos de hardware, instalaciones de transmisión y aplicaciones. Para manejarlos, el diseño de la red debe ser sencillo, general y flexible.
-
Evita opciones y paramétros estáticos: si parámetros son necesarios, es mejor que el emisor y receptor negocien un valor en vez de tener uno fijo.
-
Busca un buen diseño, no uno perfecto: a veces, los diseños son buenos pero no pueden manejar casos especiales. En vez de arruinar el diseño, las personas con casos especiales deben adaptarse al diseño.
-
Se estricto cuando envías y tolerante cuando recibes: envía paquetes que cumplan rigurosamente los estándares, pero espera paquetes que no cumplan completamente con ellas y trata con ellas.
-
Piensa en escabilidad: si el sistema debe gestionar millones de hosts y miles de millones de usuarios de manera eficaz, no se tolera ningún tipo de base de datos centralizada y la carga debe distribuirse de la manera más uniforme posible entre los recursos disponibles.
-
Considera rendimiento y costo: si la red tiene un rendimiento pobre o un costo estrafalario, nadie lo va a usar.
En la capa de red, el Internet puede ser visto como la colección de redes o Sistemas Autónomos (Autonomous Systems; ASes) que están interconectados. No hay una estructura real, pero existen varias redes troncales (backbones). Están construidas por altas bandas de ancho y routers rápidos.
El más grande de estos backbones, de los cuáles todos se conectan para llegar al resto de Internet, son llamados redes de primer nivel (tier 1 network). Unido a esos backbones están los ISPs (Internet Service Provider) que proporcionan acceso a Internet a hogares y empresas, centros de datos e instalaciones de colocación llenas de máquinas servidores y redes regionales (de nivel medio). Los centros de datos sirven gran parte del contenido que se envía a través de Internet. Adjuntos a las redes regionales hay más ISP, LAN en muchas universidades y empresas, y otras redes perimetrales.
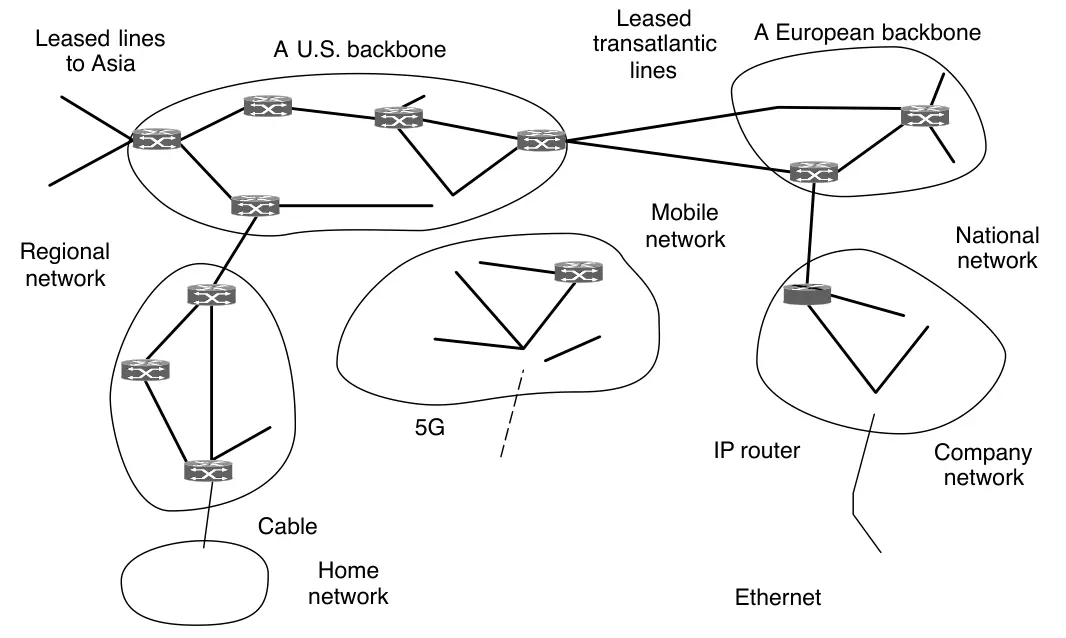
Lo que une el Internet completo es el protocolo de la capa de red, IP (Internet Protocol). Su trabajo es proveer el mejor esfuerzo de transportar paquetes desde un origen a un destino, sin importar si esas máquinas están en la misma red o si hay otras redes en el medio.
La comunicación en el Internet funciona de esta manera: la capa de transporte toma los streams de datos y los rompe para que puedan ser enviados como paquetes IP. IP routers reenvian cada paquete por el Internet, a lo largo de un camino de un router a otro, hasta llegar a destino. En el destino, la capa de red le pasa los datos a la capa de transporte, que se lo da al proceso receptor. Cuando todas las piezas llegan, la capa de red vuelve a reconstruir el datagrama original. Luego, este datagrama se entrega a la capa de transporte.
Protocolo de IP Version 4
Un datagrama IPv4 consiste en una parte de cabecera y una parte de payload. La cabecera tiene un tamaño fijo de 20 bytes y una parte variable opcional.
El campo de Version mantiene registro de cuál versión del protocolo pertenece el datagrama. Al incluír la versión, es posible tener una transición entre versiones durante un largo período de tiempo.
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| IHL |Type of Service| Total Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Identification |Flags| Fragment Offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time to Live | Protocol | Header Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Como el largo de la cabecera no es constante, un campo llamado IHL dice qué tan largo es la cabecera, en palabras de 32 bits. El Type of Service (Tipo de Servicio) originalmente era usado para saber la clase de servicio utilizado. Varias combinaciones de confiabilidad y velocidad era posible. Hoy en día, los 6 bits superiores se utilizan para marcar el paquete con su clase de servicio. Los 2 bits inferiores son usados para llevar notificación explícita de congestión.
El Total Length (Tamaño Total) incluye todo en el datagrama, incluyendo la cabecera y el dato. El tamaño total es 65,535 bytes.
El campo Identification (Identificación) es necesario para que el host destinatario determine a qué paquete pertenece un fragmento recién llegado. Todos los fragmentos de un paquete contienen el mismo valor de identificación.
Luego viene un bit sin usar. Com una broma del Día de los Inocentes, se propuso usar ese bit para marcar tráfico malicioso. Paquetes que tengan marcado el bit "malvado" serían descartados, mejorando la seguridad de la red.
Luego viene un campo de un bit relacionado a la fragmentación. DF viene de Don’t Fragment (No fragmentes). Es una orden para que los routers no fragmenten los paquetes. Es usado por el path MTU. Al marcar el datagrama con DF, el emisor sabe que el paquete llegará en una pieza o recibirá un mensaje de error.
MF viene de More Fragments (Más Fragmentos). Todos los fragmentos excepto el último tienen este bit activado. Es necesario para saber cuándo la totalidad de fragmentos han llegado.
El Fragment Offset (Desplazamiento de Fragmento) indica dónde en el paquete actual el fragmento pertenece. Todos los fragmentos excepto el último de un datagrama deben ser múltiplos de 8 bytes: la unidad de fragmento elemental. Dado que se proporcionan 13 bits, hay un máximo de 8192 fragmentos por datagrama, lo que admite una longitud máxima de paquete hasta el límite del campo Longitud total. Trabajando juntos, los campos Identification, MF y Fragment Offset se utilizan para implementar la fragmentación.
El TTL (Time to Live; Tiempo de Vida) es un contador usado para limitar el tiempo de vida de los paquetes. Debe ser decrementado en cada salto. Cuando llega a cero, el paquete es descartado y un paquete de advertencia es enviado de vuelta al host origen. Previene que los paquetes vaguen por la red por siempre.
Cuando la capa de red reensambló el paquete completo, necesita saber que hacer con él. El campo Protocol (Protocolo) dice a qué proceso de transporte darle el paquete. TCP es una posibilidad, pero también lo es UDP, y otros.
Como la cabecera contiene información sensible, contiene un Header Checksum ( Verificación de Cabecera). El algoritmo consiste en sumar todas las medias palabras de 16 bits del encabezado a medida que llegan, utilizando la aritmética en complemento a uno, y luego tomar el complemento a uno del resultado. Para los fines de este algoritmo, se supone que la suma de verificación del encabezado es cero al llegar. Esta suma de comprobación es útil para detectar errores mientras el paquete viaja a través de la red. Tenga en cuenta que se debe volver a calcular en cada salto porque al menos un campo siempre cambia (el campo TTL), pero se pueden utilizar trucos para acelerar el cálculo.
El Source Address (Dirección Origen) y Destination Address (Dirección destino) indican la dirección IP de las interfaces de red del origen y destino.
El campo Options (Opciones) fue diseñado para permitir versiones subsequentes incluír información no presente en el diseño original. Las opciones son de longitud variable. Cada uno empieza con un código de un byte identificando la opción. Algunas opciones van seguidas de un campo de longitud de opción de 1 byte y luego uno o más bytes de datos. El campo Options se rellena hasta un múltiplo de 4 bytes.
Dirección IP
IPv4 consiste en direcciones de 32 bits. Cada host y router en el Internet tiene una dirección IP que puede ser usado en el campo Source Address y Destination Address en paquetes IP.
Prefijos
Las direcciones IP son jerárquicas. Cada dirección de 32 bits está compuesta de una porción variable de red en los bits superiores y una porción de host en la parte inferior. La porción de red es la misma para todos los hosts en una misma red, como en una Ethernet LAN. Esto significa que una red corresponde a un bloque contiguo de espacio de direcciones IP. Este bloque se llama prefijo.
Direcciones IP están escritas en notación decimal con puntos. En este formato, cada uno de los 4 bytes está escrito en decimal, desde 0 hasta 255. Prefijos son escritos dando la dirección IP más baja en el bloque y el tamaño del bloque. El tamaño está determinado por el número de bits en la porción de red. El tamaño es una potencia de dos. El tamaño está escrito después del prefijo IP como una barra seguido de la longitud, por ejemplo 128.208.2.0/24.
Como la longitud del prefijo no puede ser inferido por la dirección IP, protocolos de enrutamiento deben llevar los prefijos a los routers. La longitud del prefijo corresponde a una máscara binaria de 1 en la porción de la red. Cuándo se escribe de esta manera, es llamada máscara de subred. Puede aplicarse AND con la dirección IP para extraer solo la porción de la red.
Las direcciones jerárquicas permiten que los routers reenvíen paquetes usando solo la parte de red de la dirección, reduciendo drásticamente el tamaño de las tablas de enrutamiento (de miles de millones de hosts a unos cientos de miles de prefijos).
Sin embargo, presentan dos desventajas:
-
La dirección IP depende de la ubicación del host, por lo que se requieren mecanismos como Mobile IP para mantener la misma dirección al cambiar de red.
-
La jerarquía puede ser ineficiente en el uso de direcciones si los bloques se asignan en exceso, lo que contribuyó al agotamiento del espacio IPv4. La solución propuesta es IPv6, aunque su adopción aún es gradual.
Subnets
La gestión de los números de red la realiza ICANN (Internet Corporation for Assigned Names and Numbers), que delega partes del espacio de direcciones a autoridades regionales, las cuales asignan bloques de IP a ISP y empresas.
Sin embargo, la asignación de direcciones es un proceso continuo que se complica a medida que las organizaciones crecen. Como todos los hosts de una red deben compartir el mismo prefijo, una institución (por ejemplo, una universidad) puede necesitar más direcciones para nuevos departamentos. Solicitar nuevos bloques puede ser costoso o ineficiente, especialmente si el bloque inicial ya tiene muchas direcciones sin usar. Esto muestra la necesidad de una mejor organización del direccionamiento IP.
La solución es permitir dividir el bloque de direcciones en severas partes pra uso privado como múltiples redes, mientras aún actúa como una única red hacia el exterior. Esto es llamado subnetting y las redes (como las Ethernet LAN) que resultan de dividir una red más grande son llamadas subnets (subredes).
Para dar una dirección de una subred se debe sacrificar un bit de host como mínimo.
Direccionamiento con clases
Antes de 1993, las direcciones IP se dividían en clases A, B, C, D y E, un esquema conocido como direccionamiento por clases.
-
Las clases A, B y C definían tamaños fijos de red: pocas redes muy grandes (A), redes medianas (B) y muchas redes pequeñas ©.
-
La clase D se reservaba para multicast, y la E para uso futuro.
Este diseño jerárquico resultó ineficiente, ya que muchos bloques, especialmente los de clase B, tenían miles de direcciones sin usar. Esto aceleró el agotamiento del espacio IPv4.
Para corregirlo se introdujeron las subredes y luego CIDR (Classless Inter-Domain Routing), que eliminó las clases y permitió definir prefijos de longitud variable, reduciendo el tamaño de las tablas de enrutamiento y aprovechando mejor las direcciones.
También existen direcciones especiales:
-
0.0.0.0 indica “esta red” o “este host”.
-
255.255.255.255 sirve para broadcast local.
-
127.x.x.x se usa para loopback o pruebas internas.
En resumen, CIDR sustituyó al direccionamiento por clases por ser más flexible, eficiente y escalable para el crecimiento de Internet.
Direcciones públicas y privadas y NAT
El ISP asigna a cada hogar o negocio una sola dirección IP (Dirección Pública) para el tráfico de Internet. Dentro de la red cliente, cada computadora obtiene una dirección IP única (Dirección Privada), la cual utiliza para enrutar el tráfico interno.
Justo antes de que un paquete salga de la red del cliente y vaya a Internet, la dirección IP única interna se traduce a la dirección IP pública compartida a través del NAT.
NAT (Network Address Translation) es un método para traducir direcciones privadas a públicas y viceversa.
A menudo, la caja NAT se combina en un solo dispositivo con un firewall que proporciona seguridad controlando cuidadosamente lo que entra y sale por la red de la compañía.
Los tres rangos reservados para direcciones privadas son:
| Dirección mínima | Dirección máxima | Hosts |
|---|---|---|
|
10.0.0.0 |
10.255.255.255/8 |
16.777.216 hosts |
|
172.16.0.0 |
172.31.255.255/12 |
1.048.576 hosts |
|
192.168.0.0 |
192.168.255.255/16 |
65.536 hosts |
ICMP
La operación de Internet es monitoreado cerca por los routers. Cuando algo inesperado ocurre durante el procesamiento de un paquete en un router, el evento es reportado al emisor mediante ICMP (Internet Control Message Protocol). ICMP es también usado para testear Internet. Docenas de tipos de mensajes ICMP están definidos. cada mensaje ICMP es llevado encapsulado en un paquete IP.
Los mensajes más importantes son:
| Tipo de mensaje | Descripción |
|---|---|
|
Destino inalcanzable |
El paquete no pudo ser entregado |
|
Tiempo excedido |
TTL llegó a 0 |
|
Problema de parámetro |
Campo de cabecera inválido |
|
Extinción de fuente |
Paquete de asfixia |
|
Redireccionar |
Enseñá a un router acerca de geografía |
|
Echo y Echo Reply |
Ver si una máquina está viva |
|
Timestamp request/reply |
Lo mismo que Echo, pero con marca de tiempo |
|
Anuncio/Solicitud de router |
Encuentra un router cercano |
ARP
ARP (Address Resolution Protocol) es un protocolo de red usado para mapear una dirección IP (nivel lógico) a una dirección MAC (nivel físico) dentro de una red local (LAN).
Cuando un dispositivo en una red IP quiere enviar un paquete a otro dentro de la misma red local, necesita conocer la dirección MAC del destino para poder encapsular el paquete en una trama Ethernet. Sin embargo, el dispositivo solo conoce la dirección IP del destino.
Por lo que ahí se emplea ARP:
-
El equipo origen envía una trama ARP Request a la red local (broadcast): "¿Quién tiene la IP 192.168.1.10? Responda con su MAC."
-
El equipo que tiene esa IP responde con una ARP Reply (unicast): "La IP 192.168.1.10 corresponde a la MAC AA:BB:CC:DD:EE:FF."
-
El emisor guarda esa asociación en su tabla ARP (ARP cache) para futuras comunicaciones.
Capa de transporte
La meta fundamental de la capa de transporte es proporcionar un servicio de transmisión de datos eficiente, confiable, y rentable a sus usuarios, normalmente procesos en la capa de aplicación. Para lograr esto, la capa de transporte hace uso de los servicios ofrecidos por la capa de red. El software y/o hardware en la capa de transporte que hace el trabajo se llama entidad de transporte. La entidad de transporte puede ser ubicado en el kernel del sistema operativo, en una biblioteca junto a una aplicación de red, en un proceso de usuario separado, o incluso en la interfaz de red.
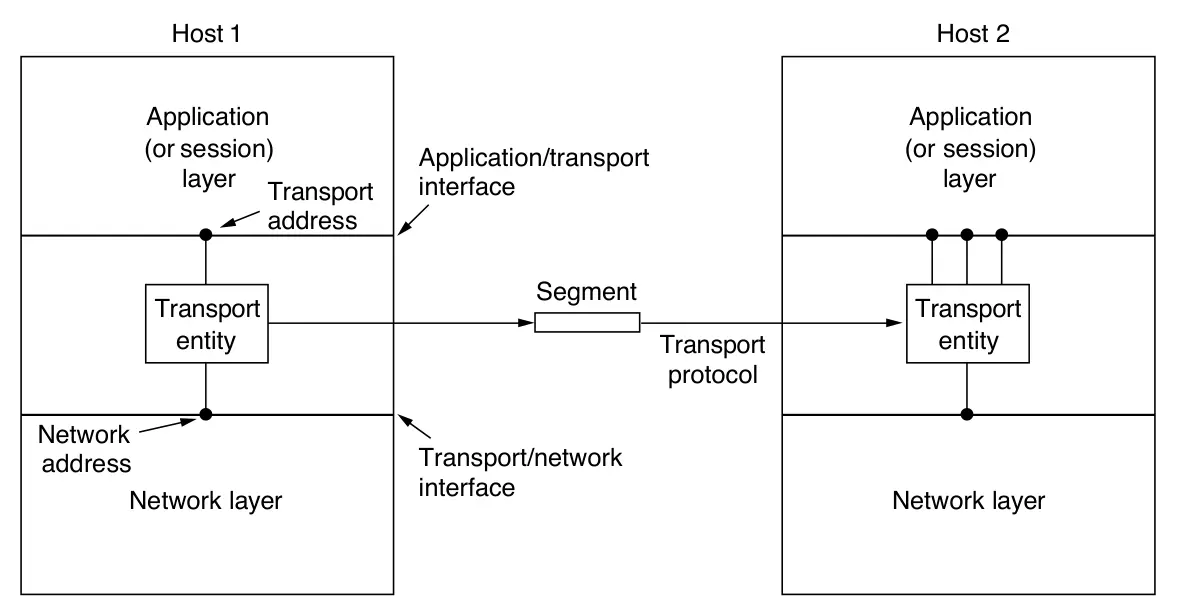
De la misma manera que hay dos tipos de servicios de red, orientado a la conexión y sin conexión, también hay dos tipos de servicios de transporte. En ambos casos, la conexión tiene tres fases: establecimiento, transferencia de datos y liberación.
El servicio de transporte es similar a la de red, pero hay algunas diferencias importantes. La principal es que el servicio de red tiene la intención de modelar el servicio ofrecido por redes reales. Redes reales pueden perder paquetes, así que el servicio de red es generalmente desconfiable.
El servicio de transporte orientado a la conexión, por el contrario, es confiable. Las redes reales no están libres de errores, pero es el propósito de la capa de transporte de proveer un servicio confiable encima de la de red.
Una segunda diferencia entre el servicio de red y el servicio de transporte es a quién están destinados los servicios. Desde la perspectiva de los endpoints de red, el servicio de red es usado solo por las entidades de red. En contraste, muchos programas ven las primitivas de transporte. Por lo que el servicio de transporte debe ser conveniente y fácil de usar.
| Primitiva | Paquete Enviado | Significado |
|---|---|---|
|
LISTEN |
(ninguno) |
Se bloquea hasta que algún proceso intente conectarse |
|
CONNECT |
PETICIÓN DE CONEXIÓN |
Activamente intenta establecer conexión |
|
SEND |
DATA |
Envía información |
|
RECEIVE |
(ninguno) |
Se bloquea hasta que un paquete de DATA llega |
|
DISCONNECT |
PETICIÓN DE DESCONEXIÓN |
Pide liberar la conexión |
Los mensajes que se envían de una entidad de transporte a otra se denominan segmentos. Algunos protocolos viejos utilizan el nombre de TPDU (Transport Protocol Data Unit).
Segmentos (intercambiados por la capa de transporte) están contenidos en paquetes (que son intercambiados por la capa de red). Que a su vez, están encapsulados en frames (que son intercambiados por la capa de enlace). Cuando un frame llega a destino, la capa de enlace procesa la cabecera del frame y, si la dirección de destino coincide, pasa el contenido del payload a la entidad de red. La entidad de red lo procesa de manera similar y lo pasa a la entidad de transporte.

Sockets
Un socket es el
punto final de una comunicación en la
capa de transporte, que actúa como interfaz
entre las aplicaciones y los protocolos de red (como
TCP o UDP). Permite que los
procesos envíen y reciban datos a través de una conexión
identificada por la cuádrupla:
(IP origen, puerto origen, IP destino, puerto destino).
El modelo de sockets fue introducido en Berkeley UNIX 4.2BSD (1983) y se convirtió en el estándar de facto para la programación de red, usado tanto en sistemas UNIX como en Windows (Winsock).
En TCP, los servidores usan los siguientes pasos:
-
SOCKET: crea el punto final de comunicación.
-
BIND: asigna una dirección IP y un puerto.
-
LISTEN: prepara la cola para solicitudes entrantes.
-
ACCEPT: espera y acepta una conexión, creando un nuevo socket para ella.
El cliente crea su socket con SOCKET y se conecta al servidor con CONNECT, estableciendo un canal bidireccional y confiable. Una vez conectados, ambos usan SEND/RECEIVE o las llamadas READ/WRITE para intercambiar datos, y CLOSE para liberar la conexión.
El socket API abstrae el servicio de transporte: normalmente ofrece un flujo confiable de bytes (TCP), pero también puede emplearse con servicios no orientados a conexión (UDP) o variantes como DCCP, que añade control de congestión.
Aunque los sockets han sido muy exitosos, presentan limitaciones: cada flujo se maneja por separado, lo que dificulta la gestión conjunta de múltiples conexiones (por ejemplo, en un navegador web). Protocolos modernos como SCTP y QUIC amplían el modelo para manejar múltiples flujos relacionados, mezclar tráfico orientado y no orientado a conexión, y usar múltiples rutas de red, ofreciendo mayor flexibilidad y eficiencia.
Elementos de los protocolos de transporte
El servicio de transporte es implementado por protocolos de transporte usado entre dos entidades de transporte.
Direccionamiento
Cuando un proceso de aplicación desea establecer una conexión con un proceso de aplicación remota, debe especificar a cuál proceso en el endpoint remoto quiere conectarse. El método normalmente utilizado es definir direcciones de transporte en las que los procesos pueden escuchar las solicitudes de conexión. En Internet, estos endpoint son llamados puertos. El término genérico se llama TSAP (Transport Service Access Point) para hablar de un endpoint específico en la capa de transporte. Similarmente, endpoints en la capa de red son llamados NSAP (Network Service Access Point). Direcciones IP es un ejemplo de NSAP.
Establecimiento de conexión
Establecer conexión puede sonar fácil, pero es realmente engañoso. Puede parecer que es suficiente que una entidad de transporte envíe un segmento de CONNECTION REQUEST al destinatario y esperar por una respuesta ACCEPTED. El problema ocurre cuando la red puede perder, retrasar, corromper y duplicar paquetes.
Three-Way Handshake
Este protocolo de establecimiento implica que un par verifique con el otro que la solicitud de conexión sea realmente actual. Host 1 elige un número de secuencia, x, y envía un segmento CONNECTION REQUEST conteniéndolo. Host 2 responde con un segmento ACK reconociendo x y anunciando su propio número de secuencia inicial, y. Finalmente, el host 1 reconoce la elección del host 2 de un número de secuencia inicial en el primer segmento de datos que envía.
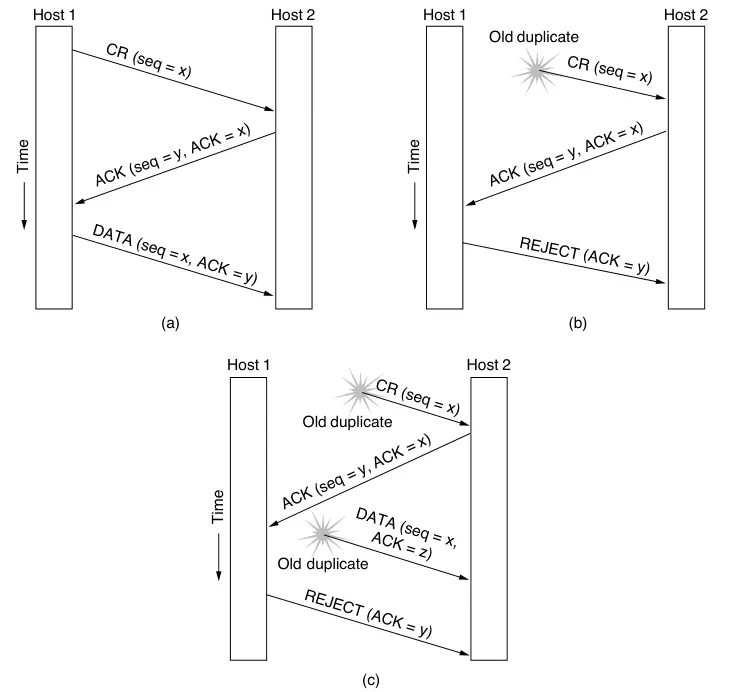
Liberación de la conexión
Liberar una conexión en la capa de transporte parece simple, pero requiere cuidado para evitar pérdida de datos o conexiones colgantes.
Existen dos métodos principales:
-
Liberación asimétrica: uno de los extremos termina la conexión de inmediato (como al colgar un teléfono). Es rápida, pero puede causar pérdida de datos si aún había información en tránsito.
-
Liberación simétrica: cada dirección de la comunicación se cierra por separado, permitiendo que un host siga recibiendo datos incluso después de enviar su solicitud de desconexión. Esto reduce la posibilidad de pérdida, pero requiere coordinación.
El problema surge porque ambos extremos deben saber con certeza que el otro está listo para desconectarse, lo que nos lleva al problema de los dos ejércitos (two-army problem).
El problema del two-army
Este problema muestra que no existe un protocolo perfecto que garantice acuerdo mutuo en un canal no confiable. Dos ejércitos (azules) deben atacar juntos, pero sus mensajeros pueden ser capturados (mensajes perdidos). Aunque uno confirme el mensaje del otro, nunca pueden tener certeza absoluta de que el último mensaje llegó, por lo que ninguno se atreve a actuar. De manera análoga, en una conexión de red, si ambos lados esperan confirmación absoluta para desconectarse, la liberación nunca ocurre.
Solución práctica
Para evitar esta situación, los protocolos reales (como TCP) permiten que cada lado cierre su parte de forma independiente. Se usa un protocolo de tres vías (three-way handshake de liberación):
-
Un host envía un DISCONNECT REQUEST (DR).
-
El receptor responde con otro DR y espera confirmación.
-
El iniciador envía un ACK, y ambos liberan su estado.
Si se pierden mensajes, temporizadores y retransmisiones aseguran que la conexión se cierre eventualmente. Aun así, puede producirse un half-open connection (una mitad cerrada y la otra activa). Para evitarlo, los sistemas aplican temporizadores de inactividad: si no hay tráfico por cierto tiempo, se desconecta automáticamente.
En resumen, la liberación de conexión es más compleja que su establecimiento, ya que requiere equilibrar seguridad, confiabilidad y cierre oportuno, evitando quedar bloqueados en espera de una confirmación imposible.